So bluesmoon wrote a blog entry on function currying in javascript. Read it first, if you've got no idea what I'm talking about.
But the example given there is hardly the *nice* one - you don't need a makeAdder(), you can sprinkle a little bit more magical pixie dust to make a maker. I remembered that I had a better sample lying around from early 2005, but unfortunately it wasn't quoted in my journal entry.
I couldn't find the exact code I wrote back then, but here's a re-do of the same idea.
function curried(f, args, arity)
{
return function() {
var fullargs = args.concat(toArray(arguments));
if(fullargs.length < arity)
{
/* recurse */
return curry(f).apply(null, fullargs);
}
else
{
return f.apply(null, fullargs);
}
};
}
function curry(f, arity)
{
if(!arity) arity = f.length;
return function() {
var args = toArray(arguments);
if(args.length < arity)
{
return curried(f, args, arity);
}
else
{
/* boring */
return f.apply(null, args);
}
};
}
Basically with the help of two closures (the two function() calls without names), I created a generic currying mechanism which can be used as follows.
function add(a,b) { return a+b;}
add = curry(add);
var add1 = add(1);
var c = add1(2);
Now, the hack works because of the arguments object available for use in every javascript function. Also every function, being an object as well, lets you look up the number of arguments (arity) it accepts by default. You can even make a full-class decorator, if you pay more attention to the scope (null, in my examples) passed to the function apply().
Here's the full code example.
--Things are are rarely simple. The function of good software is to make the complex appear to be simple.
-- Grady Booch.
I love Bokeh. Nothing stands out more in a portrait or a macro photo than the bokeh and the shallow DoF you can get out of a wide aperture lens. Here's a quick tutorial on how I managed to add to the effect of bokeh with some cheap carboard, masking tape and a bit of math.

The idea is to mask out the light from distant sources, without masking out the close up objects at all. The lens is designed such that the distant object light rays hit the lens and form large circles of light, instead of points as the beams focus before the sensor and diverge out into blurs. The math involved in designing the lens hood is to actually cut off some of the distant beams while retaining all the close object beams.
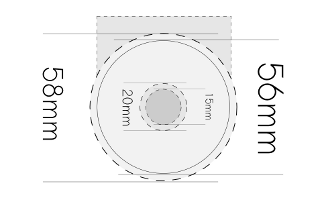
This is drawn roughly from a 50mm f/1.8 Nikkor. Anything covering the internal 15mm would block closer objects , but everything within the 20mm (approx) ring would only block distant objects. So anything you could punch out between those, would form a neat and clean bokeh image.
After trying to remember enough of 1st year engineering drawing, in my attempt to draw a heart with a 5mm tolerance, I gave up. Instead, I just took a print-out (A4) of something I could easily draw on a computer. Here's an easily printable PDF, in case you want to try it out on your own.

Here's how my Mk1 version looked like. I eventually ended up making a more collapsible version nearly completely out of duct-tape, which is far uglier, but has a slot in the top to slide in different filters. The tube collapses, making it slightly squarer and the pdf has the pull-tab version that the Mk2 uses.
Update: Someone pointed out that today's flickrblog covers this exact topic ... *ugh*, I'm an hour late. But at least, the PDF should come of some use to the lazier of you :).
--It was fun because it's something we normally wouldn't do.
-- Misty May
posted at: 03:11 | path: /tutorials | permalink |
About six years ago, in a classroom somewhere I was daydreaming while some out-of-work CS grad was trying to earn his rent, babbling about operating systems to kids who didn't want to be there. This is not about that classroom or what happened there. This is not about the memories I treasure from those days or the tumultous years that were to follow. This is about the here, now and virtual memory.
The essential problem writing code that is suppossed to be transparent is that you can't enforce your will on other code. For instance, when dealing with shared memory, it would be impossible to walk through & prevent all code using it from stomping all over the memory returned from the functions. The rather obvious solution is to deal with this is to make a copy for every case and hand it out. But doing that for all the data basically hammers over memory of the process and basically chews out the entire memory space. For a long time, I've been repeatedly debugging my entire code base with a hacked up valgrind with watchpoints. But eventually, there's that once-in-six-million errors which just won't be reproducible no matter what.
It's Not Real: The thing about memory addresses is that they're merely an abstraction. Once that idea settles down, things like fork(), CoW and mmap() start to make more and more sense. The translation from an address to a real page in memory is fairly complicated - but the actual details are irrelevant. Just like an address gets re-mapped to a different physical location when a process forks, it is possible to engineer a situation where multiple addresses point to the same location.
But why?: Sure, there's no real reason to have two addresses point to the same page, if they behave identically. But what if they behaved differently? With the help of mmap() or shmat() it's possible to create multiple virtual address spaces for the same real memory with different permissions. I discovered this particular trick thanks to someone pointing me to the Xcache Wiki. But it bears more explanation than there was. Here's how it's done.
char template[] = "/tmp/rowr.XXXXXX"; int fd = mkstemp(template); ftruncate(fd, size); void *rw = (void*)mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); void *ro = (void*)mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0); close(fd);
By mmap'ing the same fd twice, the same pages are available as RDONLY and RDWR addresses. These two addresses are different, but modifying the RW space will be reflected in the RO space - sort of like a read-only mirror of the data. A nearly identical example is possible with the use of shmat() with different permissions.
protect/unprotect: Since these are different address spaces, it is easy to distinguish between the two. Converting a RW ptr to RO, can also be accomplished simply with a little pointer arithmetic. The code would look somewhat like the version below without any bound checking. But ideally, some sort of check should be put in place to ensure double conversions don't cause errors.
int *p = (int*) rw; #define RO(p) (p) += (ro - rw); #define RW(p) (p) += (rw - ro); RO(p); *p = 42; /* causes segv */ RW(p); *p = 42; /* safe to do */
The essential task left is that all the pointers stored should be RO pointers. After storing the data, the pointers have to be flipped RO. After which, any memory walking would essentially walking over the RO "mirror" and cannot corrupt memory. All the unprotect operations would have to be inside a lock to ensure safe operation. And I do really have to thank Xcache for the idea - I'll finally have to stop hiding behind the "Zend did it!" excuse soon.
For those intrigued by my code fragments, but too lazy to fill in the blanks, here's a fully functional example.
--Don't worry about people stealing your ideas. If your ideas are any good, you'll have to ram them down people's throats.
-- Howard Aiken
I had a very simple problem. Actually, I didn't have a problem, I had a solution. But let's assume for the sake of conversation that I had a problem to begin with. I wanted one of my favourite hacked up tools to update in-place and live. The sane way to accomplish is called SUP or Simple Update Protocol. But that was too simple, you can skip ahead and poke my sample code or just read on.
I decided to go away from such a pull model and write a custom http server to suit my needs. Basically, I wanted to serve out a page feed using a server content push rather than clients checking back. A basic idea of what I want looks like this.
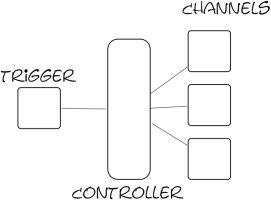
twisted.web: Twisted web makes it really easy to write an http webserver without ever wondering how an HTTP protocol line looks like. With a sub-class of twisted.web.resource.Resource, a class gets plugged into the server in-place & ready to serve a request. So, I implement a simple resource like this.
from twisted.internet import reactor, threads, defer, task
from twisted.web import resource, server
class WebChannel(resource.Resource):
isLeaf = 1
def __init__(self):
self.children = {}
def render_GET(self, request):
return "Hello World"
site = server.Site(WebChannel())
reactor.listenTCP(4071, site)
reactor.run()
Controller: The issue with the controller is mainly with the fact that it needs to be locked down to work as a choke point for data. Thankfully twisted provides twisted.python.threadable which basically lets you sync up a class with the following snippet.
class Controller(object): synchronized = ["add", "remove", "update"] .... threadable.synchronize(Controller)
loop & sleep: The loop and sleep is the standard way to run commands with a delay, but twisted provides an easier way than handling it with inefficient sleep calls. The twisted.internet.task.LoopingCall is designed for that exact purpose. To run a command in a timed loop, the following code "Just Works" in the background.
updater = task.LoopingCall(update) updater.start(1) # run every second
Combine a controller, the http output view and the trigger as a model pushing updates to the controller, we have a scalable concurrent server which can hold nearly as many connections as I have FDs per-process.
You can install twisted.web and try out my sample code which is a dynamic time server. Hit the url with a curl request to actually see the traffic or with firefox to see how it behaves. If you're bored with that sample, pull the svgclock version, which is a trigger which generates a dynamic SVG clock instead of boring plain-text. I've got the triggers working with Active-MQ and Mysql tables in my actual working code-base.
--Success just means you've solved the wrong problem. Nearly always.
I'm a very untidy tagger. I tag randomly and according to whim. Over the last year, thanks to my static tags plugin for pyblosxom, I have accumulated 150+ tags. Most of those are applied to hardly one or two entries and increasingly my tag cloud has been cluttered with such one-offs.
I spent an hour today checking out how to represent so much information into a single screen-ful. And I found a brilliant example in the penny packer extension.
So bye bye to the plaintext tags. Say guten tag to the Ishihara version.
--price tag on other side.
Frustration is my fuel. I spent an all nighter re-doing up one of my old valgrind patches to work with valgrind-3.3.1. This one was a doozy to patch up the first time (stealing rwalsh's code), but not quite very hard to keep up with the releases. The patch needs to be applied to the 3.3.1 source tree and memcheck rebuilt. It also requires the target code to be instrumented.
#include "valgrind/memcheck.h"
static int foobar = 1;
int main()
{
int *x = malloc(sizeof(int));
int wpid = VALGRIND_SET_WATCHPOINT(x, sizeof(int), &foobar);
*x = 10;
foobar = 0;
*x = 10;
VALGRIND_CLEAR_WATCHPOINT(wpid);
}
What has been added anew is the foobar conditional (you could just pass in NULL, if you always want an error). In this case the error is thrown only in first line modifying x. Setting the conditional to zero turns off the error reporting.
With the new APC-3.1 branch, I'm again hitting new race conditions whenever I change around stuff. I have no real way of debugging it in a controlled environment. But this patch will let me protect the entire shared memory space and turn on error flag as soon as control exits APC. Just being able to log all unlocked writes from Zend should go a long way in being able to track down race conditions.
Yup, frustration is my fuel.
--An intellectual is someone whose mind watches itself.
-- Albert Camus
DHCP makes for bad routing. My original problems with DHCP (i.e name resolution) has been solved by nss-mdns, completely replacing my hacky dns server - ssh'ing into hostname.local names work just fine.
But sadly, my WiFi router does not understand mdns hostnames. Setting up a tunnel into my desktop at home, so that I could access it from office (or australia for that matter), becomes nearly impossible with DHCP changing around the IP for the host.
UPnP: Enter UPnP, which has a feature called NAT Traversal. The nat traversal allows for opening up arbitrary ports dynamically, without any authentication whatsoever. Unfortunately, there doesn't seem to be any easily usable client I could use to send UPnP requests. But nothing stops me from brute-hacking a nat b0rker in raw sockets. And for my Linksys, this is how my POST data looks like.
<?xml version="1.0" ?>
<s:Envelope s:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" xmlns:s=
"http://schemas.xmlsoap.org/soap/envelope/">
<s:Body>
<u:AddPortMapping xmlns:u="urn:schemas-upnp-org:service:WANIPConnection:1">
<NewRemoteHost/>
<NewExternalPort>2200</NewExternalPort>
<NewProtocol>TCP</NewProtocol>
<NewInternalPort>22</NewInternalPort>
<NewInternalClient>192.168.1.2</NewInternalClient>
<NewEnabled>1</NewEnabled>
<NewPortMappingDescription>SSH Tunnel</NewPortMappingDescription>
<NewLeaseDuration>0</NewLeaseDuration>
</u:AddPortMapping>
</s:Body>
</s:Envelope>
And here's the quick script which sends off that request to the router.
--Air is just water with a lot of holes in it.
While working towards setting up the Hack Centre in FOSS.in, I had a few good ideas on what to do with my "free" time in there. The conference has come and gone, I haven't even gotten started and it looks like I'll need 36 hour days to finish these.
apt-share: I generally end up copying out my /var/cache/apt/archives into someone else's laptop before updating their OS (*duh*, ubuntu). I was looking for some way to automatically achieve it with a combination of an HTTP proxy and mDNS Zeroconf.
Here's how I *envision* it. The primary challenge is locating a similar machine on the network. That's where Zeroconf kicks in - Avahi service-publish and the OS details in the TXT fields sounds simple enough to implement. Having done that, it should be fairly easy to locate other servers running the same daemon (including their IP, port and OS details).
Next step would be to write a quick HTTP psuedo-cache server. The HTTP interface should provide enough means to read out the apt archive listing to other machines. It could be built on top of BaseHTTPServer module or with twisted. Simply put, all it does is send 302 responses to requests to .deb files (AFAIK, they are all uniquely named), with appropriate ".local" avahi hostnames. And assuming it can't find it in the local LAN, it works exactly like a transparent proxy and goes upstream.
Now, that's P2P.
WifiMapper: Unlike the standard wardriving toolkit, I wanted something to map out and record the signal strengths of a single SSID & associate it with GPS co-ordinates. A rather primitive way to do it would be to change the wireless card to run in monitor mode, iwlist scan your way through the place & map it using a bluetooth/USB gps device (gora had one handy).
But the data was hardly the point of the exercise. The real task was presenting it on top of a real topological map as a set of contour lines, connecting points of similar access. In my opinion, it would be fairly easy to print out an SVG file of the data using nothing more complicated than printf. But the visualization is the really cool part, especially with altitude measurements from the GPS. Makes it much simpler to survey out a conference space like foss.in than just walking around with a laptop, looking at the signal bars.
To put it simply, I've got all the peices and the assembly instructions, but not the time or the patience to go deep hack. If someone else finds all this interesting, I'll be happy to help.
And if not, there's always next year.
--Nothing is impossible for the man who doesn't have to do it himself.
-- A. H. Weiler
The "internet" is a series of tubes. So I decided to play plumber and hook up a few pipes the wrong way. What has been generally stopping me from writing too many web mashups has been the simple hurdle of making cross-domain data requests. While poking around pipes, I discovered that I could do cross-domain sourcing of data after massaging it into shape in pipes.yahoo.com.
After that blinding flash of the obvious, I picked on the latest web nitpick I've been having. Since I'm already hooked onto "The Daily Show", I've been watching (or trying to) it online from the Comedy Central website. But it is a very slow application, which shows a very small video surrounded by a lot of blank space - not to mention navigation in flash. A bit of poking around in HTTP headers showed a very simple backend API as well as an rss feed with the daily episodes. Having done a simple implementation as a shell script, I started on a Y! pipes version of it. The task was fairly intutive, though the UI takes some getting used to. Eventually, I got a javascript feed that I could just pull from any webpage, without requiring XMLHttpRequest or running into cross-domain restrictions.
You can poke around my pipe which has been used to create J002ube (say YooToobe ... so that j00z r l33t) to play the Daily Show videos. The player has zero lines of server side code and uses the Y! hosted pipes or client side code to accomplish everything.
More stuff coming up these pipes ...
--Whoever pays the piper calls the tune.
Browsing through my list of unread blog entries, I ran into one interesting gripe about lisp. The argument essentially went that the lisp parenthesis structure requires you to think from inside out of a structure - something which raises an extra barrier to understanding functional programming. And as I was reading the suggested syntax, something went click in my brain.
System Overload !!: I'm not a great fan of operator overloading. Sure, I love the "syntax is semantics" effect I can achieve with them, but I've run into far too many recursive gotchas in the process. Except for a couple of places, scapy packet assembly would be one place, I generally don't like code that uses it heavily. Still, perversity has its place.
So, I wrote a 4-line class which lets me use the kind of shell pipe syntax - as long as I don't break any python operator precedence rules (Aha!, gotcha land). The class relies on the python __ror__ operator overload. It seems to be one of the few languages that I know of which distinguishes the RHS and LHS versions of bitwise-OR.
class Pype(object):
def __init__(self, op, func):
self.op = op
self.func = func
def __ror__(self, lhs):
return self.op(self.func, lhs)
That was simple. And it is pretty simple to use as well. Here's a quick sample I came up with (lambdas; I can't live without them now).
double = Pype(map, lambda x : x * 2) ucase = Pype(map, lambda x: string.upper(x)) join = sum = Pype(reduce, lambda x,y: x+y) x = [1,2,3,4,5,6] | double | sum y = "is the answer" | ucase | join print x,y
And quite unlike the shell mode of pipes, this one is full of lists. Where in shell land, you'd end up with all operations talking in plain strings of characters (*cough* bytes), here the system talks in lists. For instance, the ucase pype actually gets a list with ['i','s' ...]. Keep that in mind and you're all set to go.
Oh, and run my sample code. Maybe there's a question it answers.
--Those who do not understand Unix are condemned to reinvent it, poorly.
-- Henry Spencer
A few months back I bought myself a cycle - a Firefox ATB. For nearly two months before heading out to Ladakh, I cycled to work. One of those days, I carried yathin's GPS along with me. So yesterday night, I dug up the GPX files, out of sheer boredom (and inspired by one of shivku's tech talks). After merging the tracks and waypoints, I managed to plot the track on a map with the help of some javascript. Here's how it looks.
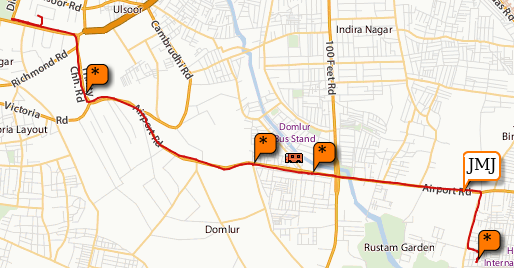
I have similar tracklogs from Ladakh, but they have upwards of 2000 points in each day, which do not play nicely with the maps rendering - not to mention the lack of maps at that zoom level. I need to probably try the Google maps api to see if they automatically remove nodes which resolve to the same pixel position at a zoom level.
I've put up the working code as well as the gpx parser. To massage my data into the way I want it to be, I also have a python gpx parser. And just for the record, I'm addicted to map/reduce/filter, lambdas and bisect.
--If you want to put yourself on the map, publish your own map.
Most wireless routers come without a DNS server to complement their DHCP servers. The ad-hoc nature of the network, keeps me guessing on what IP address each machine has. Even more annoying was the ssh man-in-the-middle attack warnings which kept popping up right and left. After one prolonged game of Guess which IP I am ?, I had a brainwave.
MAC Address: Each machine has a unique address on the network - namely the hardware MAC Address. The simplest solution to my problem was a simple and easy way to bind a DNS name to a particular MAC address. Even if DHCP hands out a different IP after a reboot, the MAC address remains the same.
Easier said than done: I've been hacking up variants of the twisted.names server, for my other dns hacks. To write a completely custom resolver for twisted was something which turned out to be trivial once I figured out how (most things are), except the dog ate all the documentation from the looks of it.
class CustomResolver(common.ResolverBase):
def _lookup(self, name, cls, type, timeout):
print "resolve(%s)" % name
return defer.succeed([
(dns.RRHeader(name, dns.A, dns.IN, 600,
dns.Record_A("10.0.0.9", 600)),), (), ()
])
Deferred Abstraction: The defer model of asynchronous execution is pretty interesting. A quick read through of the twisted deferred documentation explains exactly why it came into being and how it works. It compresses callback based design patterns into a neat, clean object which can then be passed around in lieu of a result.
But what is more interesting is how the defer pattern has been converted into a behind-the-scenes decorator. The following code has a synchronous function converted into an async defer.
from twisted.internet.threads import deferToThread
deferred = deferToThread.__get__
@deferred
def syncFunction():
return "Hi !";
The value a returned from the function is a Deferred object which can then have callbacks or errbacks attached to it. This simplifies using the pattern as well as near complete ignorance of how the threaded worker/pool works in the background.
53: But before I even got to running a server, I ran into my second practical problem. A DNS server has to listen at port 53. I run an instance of pdnsd which combines all the various dns sources I use and caches it locally. The server I was writing obviously couldn't replace it, but would have to listen in port 53 to work.
127.0.0.1/24: Very soon I discovered that the two servers can listen at port 53 on the same machine. There are 255 different IPs available to every machine - 127.0.0.2 is the same as localhost, but the different IP means that pdnsd listening on 127.0.0.1:53 does not conflict with this. Having reconfigured the two servers to play nice with each other, the really hard problem was still left.
RARP: The correct protocol for converting MAC addresses into IP addresses is called RARP. But it is obsolete and most modern OSes do not respond to RARP requests. One of the other solutions was to put a broadcast ping with the wanted MAC address. Only the target machine will recieve the packet and respond. Unfortunately, even that does not work with modern linux machines which ignore broadcast pings.
ARPing: The only fool-proof way of actually locating a machine is using ARP requests. This is required for the subnet to function and therefore does work very well. But the ARP scan is a scatter scan which actually sends out packets to all IPs in the subnet. The real question then was to do it within the limitations of python.
import scapy: Let me introduce scapy. Scapy is an unbelievable peice of code which makes it possible to assemble Layer 2 and Layer 3 packets in python. It is truly a toolkit for the network researcher to generate, analyze and handle packets from all layers of the protocol stack. For example, here's how I build an ICMP packet.
eth = Ether(dst='ff:ff:ff:ff:ff:ff') ip = IP(dst='10.0.0.9/24') icmp = ICMP() pkt = eth/ip/icmp (ans,unans)=srp(pkt)
The above code very simply sends out an ICMP ping packet to every host on the network (10.0.0.*) and waits for answers. The corresponding C framework code required to do something similar would run into a couple of hundred lines. Scapy is truly amazing.
Defer cache: The problem with flooding a network with ARP packets for every dns request is that it simply is a bad idea. The defer mechanism gives an amazing way to slipstream multiple DNS requests for the same host into the first MAC address lookup. Using a class based decorator ensures that I can hook in the cache with yet another decorator. The base code for the decorator implementation itself is stolen from the twisted mailing list.
Nested Lambdas: But before the decorator code itself, here's some really hairy python code which allows decorators to have named arguments. Basically using a lambda as a closure, inside another lambda, allowing for some really funky syntax for the decorator (yeah, that's chained too).
cached = lambda **kwargs: lambda *args, **kwarg2: \
((kwarg2.update(kwargs)), DeferCache(*args, **(kwarg2)))[1]
@cached(cachefor=420)
@deferred
def lookupMAC(name, mac):
...
The initial lambda (cached) accepts the **kwargs given (cachefor=420) which is then merged into the keyword arguments to the second lambda's args eventually passing it to the DeferCache constructor. It is insane, I know - but it is more commonly known as the curry pattern for python. But I've gotten a liking for lambdas ever since I've started using map/reduce/filter combinations to fake algorithm parallelization.
After assembling all the peices I got the following dnsmac.py. It requires root to run it (port 53 is privileged) and a simple configuration file in python. Fill in the MAC addresses of the hosts which need to be mapped and edit the interface for wired or wireless networks.
hosts = {
'epsilon': '00:19:d2:ff:ff:ff'
'sirius' : '00:16:d4:ff:ff:ff'
}
iface = "eth1"
server_address = "127.0.0.2"
ttl = 600
But it does not quite work yet. Scapy uses an asynchronous select() call which does not handle EINTR errors. The workaround is easy and I've submitted a patch to the upstream dev. With that patch merged into the scapy.py and python-ipy, the dns server finally works based on MAC address. I've probably taken more time to write the script and this blog entry than I'll ever spend looking for the correct IP manually.
But that is hardly the point  .
.
What's in a name? that which we call a rose
By any other name would smell as sweet;
-- Shakespeare, "Romeo and Juliet"
Over the last month, I've been poking around OpenMoko. The real reason was because toolz had a prototype phone with him. But the real reason I got anything done on the platform is because of the software emulation mode, with qemu-arm. The openmoko wiki has a fair bit of detail on running under QEMU - but if you just want pre-packaged ready to run QEMU images, take a look at jebba's pre-built images. All I've added to that is the qemu tun-tap network adapter ( -net nic -net tap ) so that I can scp stuff in & out of the phone image. Here's how the applications actually look on the emulator phone (it is *very* CPU heavy - if you have a Core2Duo or something, this would be a nice time to take a look at man taskset(1))
pnet on moko: Back in 2005, krokas had built the OE based packages for pnet. So essentially, building pnet ipks for OpenMoko is no different from building it for any other OE platform, especially because pnet hsa nearly no dependencies on anything beyong libc and libX11.
But the register asm() trick pnet uses to ensure that values like program counter and frame pointer are stored in the correct registers does not work on arm gcc-4.1.1. Aleksey has implemented a couple of solutions like the __asm__ barriers. But as of now, the engine is running in pure interpreter mode, which is not fast enough.
The emulator mode is pretty decent - even with the stock qemu-arm. If my interest keeps up, I'll probably try the OpenMoko patched qemu. I did build the whole toolchain and rootfs from scratch with MokoMakefile - but monotone is really painful to set up and the entire build takes a whopping 14 gigs of space on my disk. So if you're thinking of playing around with moko, don't try that first up :)
--Telephone, n.:
An invention of the devil which abrogates some of the advantages of making a disagreeable person keep his distance.
-- Ambrose Bierce
X11 programming is a b*tch. The little code I've written for dotgnu using libX11 must've damaged my brain more than second-hand smoke and caffeine overdoses put together. So, when someone asked for a quick program to look at the X11 window and report pixel modifications my immediate response was "Don't do X11". But saying that without offering a solution didn't sound too appealing, so I digged around a bit with other ways to hook into display code.
RFB: Remote Frame Buffer is the client-server protocol for VNC. So, to steal some code, I pulled down pyvnc2swf. But while reading that I had a slight revelation - inserting my own listeners into its event-loop looked nearly trivial. The library is very well written and has very little code in the protocol layer which assumes the original intention (i.e making screencasts). Here's how my code looks.
class VideoStream:
def paint_frame(self, (images, othertags, cursor_info)):
...
def next_frame(self):
...
class VideoInfo:
def set_defaults(self, w, h):
...
converter = RFBStreamConverter(VideoInfo(), VideoStream(), debug=1)
client = RFBNetworkClient("127.0.0.1", 5900, converter)
client.init().auth().start()
client.loop()
Listening to X11 updates from a real display is that simple. The updates are periodic and the fps can be set to something sane like 2 or 3. The image data is raw ARGB with region info, which makes it really simple to watch a particular window. The VNC server (like x11vnc) takes care of all the XDamage detection and polling the screen for incremental updates with that - none of that cruft needs to live in your code.
Take a look at rfbdump.py for the complete implementation - it is hardcoded to work with a localhost vnc server, but it should work across the network just fine.
--You can observe a lot just by watching.
-- Yogi Berra
I don't have flash on my machines. More than a mere security and convenience measure, it is one of those things enforced by Adobe themselves - by refusing to ship an EM64T/AMD64 build of its mozilla plugins. So when the flickr organizr went Javascript I was happy. But they took away a bit of code which made it really easy to rotate images - because you couldn't do it in Javascript.
But you can. I don't mean with some memory hogging clientside bit twiddling but with the now popular HTML 5 Canvas. So, with a few lines of Greasemonkey code, which you can pull from here, I can now push in image rotate previews back into flickr's organizr. The code has to be run outside greasemonkey land to get full access to the dom data, which I accomplish with the following script insertion.
var _s = document.createElement("script");
_s.appendChild(document.createTextNode(window.myFun.toSource() + "();"));
document.body.appendChild(_s);
And just in case you happen to be an IE user, you might want to see if EXCanvas can make my canvas code work decently there.
--enhance, v.:
To tamper with an image, usually to its detriment
Immediately after announcing the Y! mail unlimited storage, the webservices api for Y! mail has also been announced. The API is loosely modelled over NNTP and IMAP (and when I say loosely, I mean the designers read both specs *heh*) and has some really interesting features. But more importantly, now you can do cool things with it.
About 4 months back, one of the mail backend developers, Ryan Kennedy, visited Bangalore to talk about the internal workings of this awesome API. I'd gotten slightly interested because there was talk about a JSON based API which looked a lot easier to use from Javascript land. And when the hack day came around, I had managed to hack up a pretty decent Y! mail reader interface using XUL, which I named Tapestry.
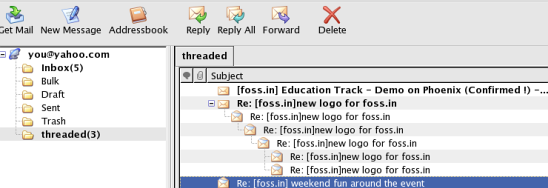
Most of the XUL code is pulled out of Thunderbird code and a large amout of the UI is controlled by CSS. The XUL css selectors are really funky - take a closer look at my css for how the different styles for messages (read, unread, replied) is css based rather than with code in Javascript. Also I played around with image slicing with CSS to put all my toolbar images into a single image and using rectangle clips to use them in appropriate buttons. In short, I had a lot of fun learning stuff to write it. But the problem was that having done it, I couldn't really show it to anyone outside the company - but now I can.
But before the demo, let me quote my bloody stupid threading code which I wrote in under twenty minutes, which unlike jwz's threading algorithm, mine handles only In-Reply-To based mail threads. But the cool part is that this function is sort of "re-entrant", so calling it multiple times from async response code manages to simulate threading as an when a message is fetched - not having to wait for all the messages to load up.
Folder.prototype.sort = function() {
for (var i=0; i<this.msglist.length; i++) {
var msg = this.msglist[i];
var parent = null;
if(!msg.parent)
{
if(msg.parentid && (parent = this.msgidmap[msg.parentid]))
{
msg.parent = parent;
parent.children.push(msg);
}
}
}
}
I don't want to attract too much attention to the hack, because of some hosting issues. So if you'd really like to see it in action and have a Y! mail beta account & run firefox 1.5/2.0, keep reading.
Ryan had hosted an in-colo mirror of my hack - it might be slow to load the images because those are on-demand and not JS pre-fetched. It is my initial release and a lot of buttons and menus don't work there. Not much has been done on top of this, but the minimum functionality works and you should probably scroll through with the keyboard which is something I *really* need. I'm sure the layout code could do with a bit of work, especially on widescreen monitors - but it was something I did for fun. The code should prove interesting to anybody who wants to read it, because I've tried a few new things with javascript and generally that has come out really well.
--Always do it right. This will gratify some people and astonish the rest.
-- Mark Twain
I suppose it is my own damn fault for not participating. But unlike last year, the hackfest was during daytime, which severly limits my coding abilities. Like so many other people who started hacking during college, my peak hours of coding lie between 7 PM and 11 PM, with the extended version running upto 3 AM - and the muse of coding cannot just turn on & off, on demand. Not to mention my laptop was showing more bad sectors than a minefield in Cambodia.
But what *really* saddens me is the first question titled jail break. I'd discovered this design flaw in chroot() quite a while back and broken out of a real production chroot. On the other hand, I'd have never really made it with the image processing example.
Maybe there was a point - but Hindsight is always 20/20.
--Given the choice between accomplishing something and just lying around, I'd rather lie around.
-- Eric Clapton
posted at: 10:53 | path: /conferences | permalink |
Finally got around to getting a debug build of libgphoto2. After a couple of hours of debugging, the problem turned to be one of design rather a real bug. I had to try a fair bit to trace the original error down to the data structure code. This is code from gphoto2-list.h.
#define MAX_ENTRIES 1024
struct _CameraList {
int count;
struct {
char name [128];
char value [128];
} entry [MAX_ENTRIES];
int ref_count;
};
And in the function gp_list_append(), there is no code which can handle possible spills. As it turns out, I had too many photos on my SD card - in one directory. The assumption that a directory contains only 1024 photos was proven to be untrue - for my SD450.
Breakpoint 3, file_list_func (fs=0x522a60,
folder=0x5a3660 "/store_00010001/DCIM/190CANON", list=0x2b11e6c38010,
data=0x521770, context=0x523d90) at library.c:3933
(gdb) p params->deviceinfo->Model
$2 = "Canon PowerShot SD450"
(gdb) p params->handles
$3 = {n = 1160, Handler = 0x528c90}
So, the code was exiting with a memory error because it ran out of 1024 slots in the folder listing code. When I explained my problems on the #gphoto channel, _Marcus_ immediately told me that I could probably rebuild my gphoto2 after changing MAX_ENTRIES to 2048 - I had already tried and failed with that. As it turns out there are two places which have MAX_ENTRIES defined and even otherwise, the libraries which use gphoto2 have various places which allocate CameraList on the stack with a struct CameraList list;, which introduces a large number of binary compatibility issues with this. But after I rebuilt libgphoto2 and gphoto2, I was able to successfully download all my photos onto my disk using the command line client, though in the process I completed b0rked gthumb.
And you've definitely gotta love the gphoto2 devs - look at this check-in about 15 minutes after my bug report.
--The capacity to learn is a gift;
The ability to learn is a skill;
The willingness to learn is a choice.
-- Swordmasters of Ginaz
After nearly a year of messing around with php extensions, I've finally sat down and written a full extension from scratch. I've used all the skeletons and ext_skel scripts, in the proper way to end up with a half-decent extension. It took me around 4 hours from an empty directory to end up with an extension which basically did what I wanted.
hidef: The define() call in php is slow. Previously the workaround to define a large chunk of constants was to use apc_load_constants, which pulled out stuff from the cache, but still had to define all constants for every one of the requests. Even beyond that the value replacement is at runtime, nearly as expensive as a $global['X']. A quick look with vld indicates the problem very clearly.
<?php
define('ANSWER', 42);
echo "The answer is ".ANSWER;
?>
line # op operands
----------------------------------------------------
2 0 SEND_VAL 'ANSWER'
1 SEND_VAL 42
2 DO_FCALL 'define', 0
3 3 FETCH_CONSTANT ~1, 'ANSWER'
4 CONCAT ~2, 'The+answer+is+', ~1
5 ECHO ~2
For a lot of code with a lot of defines(), this is a hell of a lot of CPU wasted just putting data in & reading it out, where a substitution would be much better. But first things first, I got a basic extension which would parse a .ini file and define the constant with some magic flags - this is what you'd put into the ini file.
[hidef] float PIE = 3.14159; int ANSWER = 42;
The extension reads this once when apache starts up and puts into the php's constants section. The constant is pushed in with the CONST_PERSISTENT flag which means that the constant lives across requests. Recently, Dmitry had put in a new bit into this mix - CONST_CT_SUBST which marks constants as canditates for compile time substitution.
After adding compile-time substitution into the extension code, the code generator replaces constants as & when it runs into them. And here's what the bytecode looks like.
<?php
echo "The answer is ".ANSWER;
?>
line # op operands
--------------------------------------------
2 0 CONCAT ~0, 'The+answer+is+', 42
1 ECHO ~0
You don't need to be a genius to figure out which one would be faster. But the other gopal had done some benchmarks which didn't seem to show enough difference between constants and literals. So, I wrote a quick & dirty benchmark with 320 defines and adding them all up in the next line. Here is the before and after numbers.
| Before | After |
|---|---|
| 380.785 fetches/sec | 930.783 fetches/sec |
| 14.2647 mean msecs/first-response | 6.30279 mean msecs/first-response |
But the true significance of these few hundred lines of code fades a bit when you pull in APC into the mix. With APC enabled I was still expecting a significant difference in performance and here it is.
| Before | After |
|---|---|
| 976.29 fetches/sec | 1519.38 fetches/sec |
| 4.95603 mean msecs/first-response | 3.15688 mean msecs/first-response |
The numbers are seriously biased, because for most code the major bottleneck is their DB and therefore I/O bound. But if this small bit of code helps shave off a few microseconds of CPU time, for a few hours of my hacking time, it is pretty good when you consider the scale factor.
So, without further ado - here's hidef 0.0.1 - should build fine for both php5 and php4. And if you feel the urge to fix something in there or write documentation, go for it ! :)
--If you don't know what procrastination is just look up the definition tomorrow.
Repeat after me, three times - C++ is not C. This is a fact which has to be hammered into every programmer who claims to know C/C++, with a nice clue bat if necessary. But in this case, it was more of g++ isn't gcc and only for those who use RHEL4.
Here's a bit of working code in C99 which is totally different from C89 (otherwise known as your dad's C standard) - which is technically speaking, legal C++ code as well.
/* compile with gcc -std=c99 */
#include <limits.h>
#include <stdio.h>
int main()
{
printf("Maximum value for unsigned long long: %llu\n", ULLONG_MAX);
}
But the exact same code was not working when treated as C++ code. For a few versions of glibc, no matter which C++ standard you used, ULLONG_MAX wouldn't be defined. Not even if the code segment is enveloped in an extern "C" block.
As it turns out, this was a quirk of the glibc's extension to the C pre-processor - include_next. Rather than include the standard /usr/include/limits.h, what the first include statement does is pull the limits.h file from the compiler include files - from /usr/lib/gcc/.... You can figure this out by running g++ -M limit.cpp, which dumps a pre-order traversal of the include hierarchy.
And the definition of ULLONG_MAX was probably written by someone who never expected a compiler include file to be included directly from a user program - and rightly so. Except, there is no real way to fix the include order for such similarly named files.
Eventually, the fix was to use ULONG_LONG_MAX instead of the slightly shorted ULLONG_MAX. But the glibc bug has been fixed for a while - was just not critical enough to be pushed to all machines.
--The strictest limits are self-imposed.
-- House Harkonnen, Frank Herbert.
I've been playing around with twisted for a while. It is an excellent framework to write protocol servers in python. I was mostly interested in writing a homebrew DNS server with the framework, something which could run plugin modules to add features like statistical analysis of common typos in domain names and eventually writing up something which would fix typos, like what opendns does.
To my surprise, twisted already came with a DNS server - twisted.names. And apparently, this was feature compatible with what I wanted to do - except that there was a distinct lack of documentation to go with it.
7 hours and a few coffees later, I had myself a decent solution. Shouldn't have taken that long, really - but I was lost in all that dynamically typed polymorphism.
from twisted.internet.protocol import Factory, Protocol
from twisted.internet import reactor
from twisted.protocols import dns
from twisted.names import client, server
class SpelDnsReolver(client.Resolver):
def filterAnswers(self, message):
if message.trunc:
return self.queryTCP(message.queries).addCallback(self.filterAnswers)
else:
if(len(message.answers) == 0):
query = message.queries[0]
# code to do a dns rewrite
return self.queryUDP(<alternative>).addCallback(self.filterAnswers)
return (message.answers, message.authority, message.additional)
verbosity = 0
resolver = SpelDnsReolver(servers=[('4.2.2.2', 53)])
f = server.DNSServerFactory(clients=[resolver], verbose=verbosity)
p = dns.DNSDatagramProtocol(f)
f.noisy = p.noisy = verbosity
reactor.listenUDP(53, p)
reactor.listenTCP(53, f)
reactor.run()
That's the entire code (well, excluding the rewrite sections). Should I even bother to explain how the code works ? It turned out to be so childishly simple, that I feel beaten to the punch by the twisted framework. To actually run it in server mode, you can start it with twistd -y speldns.py and you have your own DNS server !
In conclusion, I hope I have grossed a few of you out by trying to do soundex checks on dns sub-domains.
--DNS is not a directory service.
-- Paul Vixie
Weak symbols are a poor man's version of linker land polymorphism. A weak symbol can be overriden by a strong symbol when a linker loads an executable or shared object. But in the absence of a strong sym, the weak version is used without any errors. And that's how it has worked for a long long time in ELF binary land.
But then dlopen() went and changed the rules. When you load a shared library with RTLD_GLOBAL, the symbols became available to all the other shared objects. And the libc rtld.c had the runtime magic required to make this happen (and the unloading was even harder).
Then one fine day, Weak Symbols were empowered. In dynamic shared objects (DSO), there was no difference between weak and strong. It has been so since the glibc-2.1.91 release.
Now let me backtrack to my original problem. Once upon a time, there was a php extension which used an apache function, ap_table_set() to be precise. But for the same php extension to be loadable (though not necessarily useful) inside a php command line executable - the external symbol had to be resolved. That's where a weak symbol proves itself invaluable - a libapstubs.a could be created with a weak ap_table_set, so that as long as the extension is run outside apache, the stub function will get called.
But it wasn't working on linux (works on FreeBSD). And except for the extension, we weren't able to write a single test case which would show the problem. And then I ran into a neat little env variable - LD_DYNAMIC_WEAK. Just set it to 1 and the rtld relegates the weak symbols back into the shadows of the strong ones. But that raised a few other problems elsewhere and I personally was lost.
But now I know where exactly this went wrong. Php was using a glibc dl flag called RTLD_DEEPBIND (introduced in zend.h,1.270). This seems to be a glibc feature and the flag bit is ignored by the FreeBSD libc - which was running the php module happily. As you can read in that mail, it looks up the local shared object before it starts looking in the global scope. Since libapstubs was a static .a object, the local scope of the ext .so did contain the dummy ap_table_set() and since glibc rltd was ignoring the weak flags, that function was called instead of the real apache one.
I'm perfectly aware that RTLD_DEEPBIND can save a large amount of lookup time for shared objects built with -fPIC, because of the PLT (we've met before). But if you are trying to use it to load random binaries (like extension modules), here's a gotcha you need to remember.
Now to get back to doing some real work :)
--A wise person makes his own decisions, a weak one obeys public opinion.
Flockr generates digraphs out of your flickr contacts. This is what has triggered me to go off the straight & narrow path of low level programming into hacks with Graph networks and x-mixed-replace. Anyway, what is done is done - take a look at a canned demo if you are on Firefox 1.5 and above (can't host cgi scripts).

The really hard part of the above code comes out of the simple fact that HTML Canvas is totally pixel based. You cannot attach an event to a small circle drawn as lines & figures. The code inside graph.js has a class called NodeHandler which sort of implements event masks and handlers for a node I've drawn on canvas. The code uses a hashed bucket to determine which all nodes it needs to iterate over, rather than loop over every node in the graph for every mouse move - harsh lessons learnt from dotgnu's winforms. It works better than I'd expected of Javascript and certainly seems snappy enough.
Now, I'm off hacks for a while ... time to vent some energy on real code.
--An empty canvas has more potential for greatness than any painting.
For the entire weekend and a bit of Monday, I've been tweaking my di-graphs to represent flickr entries and in general, that has produced some amazing results. For example, I have 700+ people in a Contact of a Contact relationship and nearly 13,000 people in the next level of connectivity. But in particular, I was analyzing for cliques in the graph - a completely connected subgraph in which every node is connected to every other. For example, me, spo0nman, premshree and teemus was the first clique the system identified (*duh!*).
Initially, I had dug my trusty Sedgewick to lookup graph algorithms and quickly lost myself in boost::graph land. STL is not something I enjoy doing - this was getting more and more about my lack of const somewhere rather than real algorithms. And then I ran into NetworkX in python.
NetworkX is an amazingly library - very efficient and very well written. The library uses raw python structures as input and output and is not wrapped over with classes or anything else like that. The real reasons for this came up as I started using python properly rather than rewrite my C++ code in python syntax. When I was done, I was much more than impressed with the language than the library itself. Here are a few snippets of code which any C programmer should read twice :)
def fill_nodes(graph, id, contacts):
nodes = [v.id for v in contacts]
edges = [(id, v.id) for v in contacts]
graph.add_nodes_from(nodes)
graph.add_edges_from(edges)
def color_node(graph):
global cmap
node_colours = map(
lambda x: cmap[graph.degree(x) % cmap.length],
graph.nodes())
Or one of the more difficult operations, deleting unwanted nodes from a graph.
# trim stray nodes
def one_way_ride(graph):
deleted_nodes = filter(
lambda x: graph.degree(x) == 1,
graph.nodes())
deleted_edges = filter(
lambda x: graph.degree(x[0]) == 1 or
graph.degree(x[1]) == 1,
graph.edges())
graph.delete_edges_from(deleted_edges)
graph.delete_nodes_from(deleted_nodes)
The sheer fluidity of the lambda forms are amazing and I'm getting a hang of this style of thinking. And because I was doing it in python, it was relatively easy to create a cache for the ws requests with cPickle. Anyway, after fetching all the data and all this computation, I managed to layout the graph and represent it interactively, in the process forgetting about clique analysis, but that's a whole different blog entry anyway.
--The worst cliques are those which consist of one man.
-- G. B. Shaw
I've been playing around with some stuff over the weekend, which eventhough runs in a browser, needs continous updates of data while maintaining state. So I tried to a socket-hungry version of server push which has been called COMET. Now, this technique has come into my notice because of a hack which bluesmoon did, except I had to reinvent for python what CGI.pm did for bluesmoon by default.
But first, I mixed over a couple of the client side bits. Instead of relying on XHR requests, which are all bound & gagged by the security model, I switched to a simpler cross-domain IFRAME. But what's really cool here is that I use a single request to push all my data through, in stages, maintaining state. So here's a bit of code, with technical monstrosity hidden away.
#!/usr/bin/python import sys,time from comet import MixedReplaceResponse content = "<html><body><h1>Entry %d</h1></body></html>"; req = new MixedReplaceResponse() for i in range(0,10): req.write(content % i) req.flush() time.sleep(3) req.close()
The MixedReplaceResponse is a small python class which you can download - comet.py. But the true beauty of this comes into picture only when you put some scripting code in what you send. For example here's a snippet from my iframe cgi code.
wrapper = """
<html><body> <script> if(window.parent) {
%s
} </script></body></html>
""";
script = ("window.parent.updateView(%s);" % json.write(data))
req.write(wrapper % script)
req.flush()
As you can clearly see, this is only a minor modification of the json requests which I'd been playing with. But underneath the hood, on the server side, this is a totally different beast, totally socket hungry and does not scale in the apache cgi model. Interesting experiment nonetheless.
Now, if only I could actually host a cgi somewhere ...
--To see a need and wait to be asked, is to already refuse.
One of the first cool things I saw in flickr was notes. They're those small boxes which you can drag across a picture to mark off a region or add some more context to something. When I recently started linking in flickr photos to my blog, these were some things I missed. Without a small box saying "That thin line is the road", a few of the more impressive photographs I'd got were quite ordinary landscapes.
While looking at the new flickr apis - especially the JSON apis, something clicked somewhere. Finally, there seemed to be a very nice way to do cross-domain requests from my blog (or literally any web-page) to flickr to read notes, tags and other information. Minimilastically, this is what my code does :
function myMethod(data)
{
alert(data["stat"]);
}
var photos_get_info = "http://api.flickr.com/services/rest/?"
+ "method=flickr.photos.getInfo&api_key="+api_key
+ "&format=json&jsoncallback=myMethod"
+ "&photo_id=" + photo_id + "&secret="+secret;
/* cross-domain request */
(function(url) {
var _s = document.createElement("script");
_s.src = url;
document.body.appendChild(_s);
})(photos_get_info);
The photo_id and secret are the two parts in a flickr image url, the first part is the id and the second the secret. Provided you've given valid data there, flickr will respond to your data load with something like the following data.
myMethod({"photo" : .... , "stat" : "ok" });
Which when interpreted by the browser, magically seems to call your callback myMethod. Isn't that beautiful or what ? Of course, this workaround is not necessarily new information for me - but pretty damn convenient. Either way, once you've got the cross-domain data, it is only a few steps away from taking that data and displaying it.
Take a closer look at the ugly javascript if you want, or just look at the pretty pictures or funny pictures or even your own pictures.
{kind=link}
{kind=link}
Actually, more than being able to embed notes in my blog, this has brought along an unexpected advantage. With this script, the flickr notes are scaled according to the picture, so that you can have notes for a large or original size picture. Maybe I should make this a GM script so that I can do the same in flickr's zoom.gne pages.
Either way, the fun ends here.
--It's difficult to see the picture when you are inside the frame.
One of the lamest hacks, we've ever done is something called Debt-o-Matic. I know spo0nman has already blogged about this, but there's more to this hack than meets the eye. To start with, this was the first hack which went from decision to action in around twenty minutes. And then we *designed*.


Through out this period, I was being active and generally bouncing around. Sad to say, but I was the product manager for the hack - doing little and suggesting a lot. But I redeemed myself by producing a kick-ass logo for for our hack. And after all that, we finally had ourselves a product before the morning dawned and an idea left to finish.

Remember the good old days in college where we used to adjust debts by transferring debts around ? We wrote up something which would find circles of debt and remove the smallest amount from all of them, by virtually circulating it. Not rocket science, but useful as this system can do it automatically. But stating privacy concerns, we cut down that to a A -> B -> C scenario, which is trimmed into an A -> C scenario.
We never got around to building the audit trail and details view stuff because it was getting late for our flight to Delhi. And off we went, leaving teemus to submit the hack, but there still was nobody to present it.
In short, we had fun.
--Forgetfulness, n.:
A gift of God bestowed upon debtors in compensation for their destitution of conscience.
Thanks to all my firefox proxy.pac DNS irritations, I finally decided to ditch my ssh -D socks proxy for a tunnel into a squid. While I set up the firewall and enough protection for the proxy, I wanted to enable password protection on it. But basic authentication is not much of a protection and I didn't want to create a dummy user in the systtem to use this. Basically, I wrote my own squid authenticator - a simple enough task in hindsight.
If you inspect your default squid.conf, you'll find a line somewhat like this. This is your authenticator hook, which is a program which reads a single line in and outputs either "OK" or "ERR".
auth_param basic program <uncomment and complete this line>
Now, after I know how the authentication works, it was as easy as pi. A simple enough script in whatever language you're comfortable in will do - I prefer python over perl and this sample's in py.
#!/usr/bin/python
import os, sys,re
LINE_PAT = re.compile("([a-z_]*) (.*)\n")
u = sys.stdin.readline()
while u:
m = LINE_PAT.match(u)
if m:
(user,pw) = m.groups()
if authenticate(user,pw):
print "OK"
else:
print "ERR"
else:
print "ERR"
sys.stdout.flush()
u = sys.stdin.readline()
sys.exit(0)
Define your own version of authenticate, for example mine accepts a password that is "<fixed>.<OTP>" and the OTP is regenerated every 4 hours (not a very secure channel for transmitting that, but it works). You could probably build something similar to what RSA keycards use, which is basically the same principle.
auth_param basic program /usr/local/bin/sq_custom_auth acl password proxy_auth REQUIRED # password protected http_access allow password
Voila, you have a squid authentication that doesn't need a system account. Of course, there are more proper ways of doing this - like backing it with Mysql, LDAP or even RADIUS. But for a non-sysadmin like me, it needn't scale or be absolutely bulletproof. Probably took me much less time to do this, than write out this blog entry. But I wrote this so that sometime later, I can come back and look at this instead of remembering how to do this.
--Always think of something new; this helps you forget your last rotten idea.
-- Seth Frankel
I got irritated of getting kicked off irc around 20 times and the associated ghosting and renicking. So I sat down and wrote something that would keep me t3rmin4t0r on freenode.
import re,xchat
nick_pat = re.compile(":(?P<nick>[^!]*)!(?P<user>[^@]*)@(?P<host>.*)")
def renick(*args):
nickhost = args[0][0]
m = nick_pat.match(nickhost)
if(m.groups()[0] == "t3rmin4t0r"):
xchat.command("nick t3rmin4t0r");
xchat.hook_server('QUIT', renick)
Load that up with /py load ~/.xchat2/pylugins/re-t3.py and now I can stop worrying about being stuck as a mere gopal__ on irc.
--Who steals my purse steals trash; ’tis something, nothing;
How many times have you run into a CD which would let you play a file off the disk, but wouldn't let you copy it out ? It is one of those irritating problems, which should really have a simple solution. Most AVI files are fairly error tolerant, they wouldn't really care if a few KB are missing from the video stream, as long as they can locate the next key-frame, it will keep playing forward. So playing an AVI off scratched media will often work without much disturbance, but it would be near impossible for a normal copy program to create a copy of the file.
Even though you can accomplish the same task with dd noerror, it tries to recover every bit of data possible which is not something that you require when you are trying to copy a large number of files off a DVD. So I basically hacked up a small program which would leave zero-padded 4k holes wherever the disk area wasn't readable. The program accomplishes this by the easiest way possible - by running the following in a loop.
if(i < len)
{
if(fork())
{
i += BLOCK_SIZE;
}
else
{
copyblock(dest, src, i, BLOCK_SIZE, len);
exit(0);
}
}
Now, that'd obviously result in a very near fork-bomb of your machine while copying a 700Mb file. So I added code so that a fixed number of processes are spawned to start off while the next process is started off only after one of the processes die off. Also, to improve the copying efficency I increased the BLOCK_SIZE to 64k but still wanted to make sure that the size of the errored blocks weren't more than 4k. So I added a retry section, which would spawn 16 processes each handling a 4k block of the errored 64k.
deadproc = wait(&status);
if(WIFSIGNALED(status) && WTERMSIG(status) == SIGBUS)
{
/* retry */
}
Now the awesome part of this program is not how it works. The really cool thing is to attach strace to this and watch the fork() in operation as well as the SIGCHILD return back. Also it is a very simple example of how something like APC shares memory between all the apache children with mmap (though without any locks). There might just be a better approach for this particular problem, using signal(SIGBUS), but that is left as an exercise to the reader.
Here's the code for the curious. And remember, if you are still running on x86 32 bit, memory mapping big files might cause your OS to run out of address space.
--(1) Never draw what you can copy.
(2) Never copy what you can trace.
(3) Never trace what you can cut out and paste down.
The problem with taking photos in a moving car is that it is very hard to get the baseline of the photo on the horizontal. So eventually to get a decent pic, you need to rotate the photo. But after rotation, you need to crop it back to a square. All operations which take time and is relatively annoying. So, I wrote a gimp script.
r = math.sqrt(x*x + y*y)/2 # as calculated for top left corner theta = math.radians(45) phi = math.radians(45 + angle) dx = r * math.cos(phi) - r * math.cos(theta) # -1 * because as the angle comes down, our y decreases dy = -1 * (r * math.sin(phi) - r * math.cos(theta))
Basically, this python-fu script (rot-crop.py) does both operations together and gives you a cropped rectangular image.


rotated 6 odd degrees
Script-Fu is esoteric stuff, but the python plugins can actually be read, understood and written by mere mortals like me.
--My geometry teacher was sometimes acute, and sometimes obtuse, but always,
always, he was right.
[That's an interesting angle. I wonder if there are any parallels?]
Been pissed all day due to the stupid advertisements on Yahoo groups emails. Every mail I read has a very irritating sidebar which I find no use for. So I added the following 3 lines to my ~/.thunderbird/*default/chrome/userContent.css .
#ygrp-sponsor, #ygrp-ft, #ygrp-actbar, #ygrp-vitnav {
display: none;
}
Much better. Ad block is one of those things where being the minority is sometimes an advantage.
--If we don't watch the advertisments it's like we're stealing TV.
-- Homer Simpson
Since I do not run any server side code, I'm always playing around with new client side tricks. For example, the XSL in my RSS or the sudoku solver. But recently I was playing with the HTML Canvas and was wondering whether there was some other way I could generate images client side with javascript. And it turns out that you can.
Tool of choice for moving image data from a javascript variable into a real image is a data: URI. And it also helps that windows bitmaps are so easy to generate, after all it was designed with simplicity in mind. Here's a chunk of code which should in most ways be self explanatory.
function Bitmap(width, height, background)
{
this.height = height;
this.width = width;
this.frame = new Array(height * width);
}
Bitmap.prototype.setPixel = function setPixel(x,y, c) {
var offset = (y * this.width) + x;
/* remember that they are integers and not bytes :) */
this.frame[offset] = c;
};
Bitmap.prototype.render = function render() {
var s = new StringStream();
s.writeString("BM");
s.writeInt32(14 + 40 + (this.height * this.width * 3)); /* 24bpp */
s.writeInt32(0);
s.writeInt32(14+40);
/* 14 bytes done, now writing the 40 byte BITMAPINFOHEADER */
s.writeInt32(40); /* biSize == sizeof(BITMAPINFOHEADER) */
s.writeInt32(this.width);
s.writeInt32(this.height);
s.writeUInt16(1); /* biPlanes */
s.writeUInt16(24); /* bitcount 24 bpp RGB */
s.writeInt32(0); /* biCompression */
s.writeInt32(this.width * this.height * 3); /* size */
s.writeInt32(3780); /* biXPelsPerMeter */
s.writeInt32(3780); /* biYPelsPerMeter */
s.writeInt32(0); /* biClrUsed */
s.writeInt32(0); /* biClrImportant */
/* 54 bytes done and we can start writing the data */
for(var y = this.height - 1; y >=0 ; y--)
{
for(var x = 0; x < this.width; x++)
{
var offset = (y * this.width) + x;
s.writePixel(this.frame[offset] ? this.frame[offset] : 0);
}
}
return s;
};
Well, that was easy. Now all you have to do is generate a base64 stream from the string and put in a data: URL. All in all it took a few hours of coding to get Javascript to churn out proper Endian binary data for int32 and uint16s. And then it takes a huge chunk of memory while running because I concatenate a large number of strings. Ideally StringStream should have just kept an array of strings and finally concatenated them all into one string to avoid the few hundred allocs the code currently does. But why optimize something when you could sleep instead.
Anyway, if you want a closer look at the complete code, here's a pretty decent demo.
--Curiousity is pointless.
I recently discovered an easy way to inspect php files. So xdebug has a cvs module in their cvs called vle. This prints out the bytecode generated for php code. This lets me actually look at the bytecode generated for a particular php data or control structure. This extension is shining a bright light into an otherwise dark world of the ZendEngine2.
Let me pick on my favourite example of mis-optimisation that people use in php land - the HereDoc. People use heredoc very heavily and over the more mundane ways of putting strings in a file, like the double quoted world of the common man. Some php programmers even take special pride in the fact that they use heredocs rather than use quoted strings. Most C programmers use it to represent multi-line strings, not realizing php quoted strings can span lines.
<?php echo <<<EOF Hello World EOF; ?>
Generates some real ugly, underoptimised and really bad bytecode. Don't believe me, just look at what the vle dump looks like.
line # op ext operands
-------------------------------------------------
3 0 INIT_STRING ~0
1 ADD_STRING ~0, ~0, '%09'
2 ADD_STRING ~0, ~0, 'Hello'
3 ADD_STRING ~0, ~0, '+'
4 ADD_STRING ~0, ~0, 'World'
4 5 ADD_STRING ~0, ~0, ''
6 ECHO ~0
That's right, every single word is seperately appended to a new string and after all the appends with their corresponding reallocs, the string is echoed and thrown away. A really wasteful operation, right ? Well, it is unless you run it through APC's peephole add_string optimizer.
Or the other misleading item in the arsenal, constant arrays. I see hundreds of people use php arrays in include files to speed up the code, which does indeed work. But a closer look at the array code shows a few chinks which can actually be fixed in APC land.
<?php
$a = array("x" => "z",
"a" => "b",
"b" => "c",
"c" => "d");
?>
Generating the following highly obvious result. Though it must be said that these are hardly different from what most other VMs store in bytecode, they are limited by the fact that they have to actually write the code (minus pointers) to a file. But Zend is completely in memory and could've had a memory organization for these arrays (which would've segv'd apc months before I ran into the default array args issue).
line # op ext operands
-----------------------------------------------------------
2 0 INIT_ARRAY ~0, 'z', 'x'
3 1 ADD_ARRAY_ELEMENT ~0, 'b', 'a'
4 2 ADD_ARRAY_ELEMENT ~0, 'c', 'b'
5 3 ADD_ARRAY_ELEMENT ~0, 'd', 'c'
4 ASSIGN !0, ~0
7 5 RETURN 1
6 ZEND_HANDLE_EXCEPTION
This still isn't optimized by APC and I think I'll do it sometime soon. After all, I just need to virtually execute the array additions and cache the resulting hash as the operand of the assign instead of going through this stupidity everytime it is executed.
Like rhysw said, "Make it work, then make it work better".
--Organizations can grow faster than their brains can manage them.
-- The Brontosaurus Principle
Valgrind is one of the most common tools people use to debug memory. Recently while I was debugging APC, the primary problem I have is of php Zend code writing into shared memory without acquiring the locks required. I had been debugging that with gdb for a while, but gdb is just dead slow for watching writes to 16 Mb of memory and generating backtraces.
The result of all that pain was a quick patch on valgrind 3.1.1. The patch would log all writes to a memory block with backtraces. But valgrind does not have a terminal to type into midway, unlike gdb. So the question was how to indicate a watchpoint. Valgrind magic functions were the answer. The magic functions can pass a parameter to valgrind while in execution. This is a source hack and is a hell of a lot easier to do than actually breaking in gdb and marking a breakpoint everytime you run it. So here's how the code looks like :-
#include "valgrind/memcheck.h"
int main()
{
int * k = malloc(sizeof(int));
int x = VALGRIND_SET_WATCHPOINT(k, sizeof(int));
modify(k);
VALGRIND_CLEAR_WATCHPOINT(x);
}
That is marked out in the normal code with the following assembly fragment.
movl $1296236555, -56(%ebp)
movl 8(%ebp), %eax
movl %eax, -52(%ebp)
movl $4, -48(%ebp)
movl $0, -44(%ebp)
movl $0, -40(%ebp)
leal -56(%ebp), %eax
movl $0, %edx
roll $29, %eax ; roll $3, %eax
rorl $27, %eax ; rorl $5, %eax
roll $13, %eax ; roll $19, %eax
movl %edx, %eax
movl %eax, -12(%ebp)
This doesn't do anything at all on a normal x86 cpu but inside the valgrind executor, it is picked up and delivered to mc_handle_client_request where I handle the case and add the address and size, to the watch points list.
So whenever a helperc_STOREV* function is called, the address passed in is checked against the watchpoints list, which is stored in the corresponding primary map of access bits. All of these bright ideas were completely stolen from Richard Walsh patch for valgrind 2.x. But of course, if it weren't for the giants on whose shoulders I stand ...
bash$ valgrind a.out ==6493== Watchpoint 0 event: write ==6493== at 0x804845E: modify (in /home/gopalv/hacks/valgrind-tests/a.out) ==6493== by 0x80484EA: main (in /home/gopalv/hacks/valgrind-tests/a.out) ==6493== This watchpoint has been triggered 1 time ==6493== This watchpoint was set at: ==6493== at 0x80484DB: main (in /home/gopalv/hacks/valgrind-tests/a.out)
Now, I can actually run a huge ass set of tests on php5 after marking the APC shared memory as watched and see all the writes, filter out all the APC writes and continue to copy out the other written segments into local memory for Zend's pleasure.
Writing software gives you that high of creating something out of nearly nothing. Since I am neither a poet nor a painter, there's no other easy way to get that high (unless ... *ahem*).
--Mathemeticians stand on each other's shoulders while computer scientists stand on each other's toes.
-- Richard Hamming
Some time in late 2002, I got to see a clear picture of what interpreter optimisation is all about. While I only wrote a small paragraph of the Design of the Portable.net Interpreter, I got a good look at some of the design decisions that went into pnet. The history of the CVM engine aside, more recently I started looking into the Php5 engine core interpreter loop. And believe me, it wasn't written with raw performance in mind.
The VM doesn't go either the register VM or stack VM way, there by throwing away years of optimisations which have gone into either. The opcode parameters are passed between opcodes in the ->result entry in each opcode and which are used as the op1 or op2 of the next opcode. You can literally see the tree of operations in this data structure. As much as it is good for data clarity, it means that every time I add two numbers, I write to a memory location somewhere. For example, I cannot persist some data in a register and have it picked up by the latter opcode - which is pretty easy to do with a stack VM.
Neither did I see any concept called verifiability, which means that I cannot predict output types or make any assumptions about them either. For example, the following is code for the add operation.
ZEND_ADD_SPEC_VAR_VAR_HANDLER:
{
zend_op *opline = EX(opline);
zend_free_op free_op1, free_op2;
add_function(&EX_T(opline->result.u.var).tmp_var,
_get_zval_ptr_var(&opline->op1, EX(Ts), &free_op1 TSRMLS_CC),
_get_zval_ptr_var(&opline->op2, EX(Ts), &free_op2 TSRMLS_CC) TSRMLS_CC);
if (free_op1.var) {zval_ptr_dtor(&free_op1.var);};
if (free_op2.var) {zval_ptr_dtor(&free_op2.var);};
ZEND_VM_NEXT_OPCODE();
}
Since we have no idea what type of zval is contained in the operators, the code has to do a set of conversion to number. All these operations involve basically a conditional jump somewhere (aka if) which are what we're supposed to be avoiding to speed up.
Neither could I registerify variables easily, because there was a stupid CALL based VM (which is flexible enough to do some weird hacks by replacing opcodes) which throws away all variables in every scope. That's some serious stack space churn, which I can't force anyone to re-do. At least, not yet. So inspite of having a CGOTO core, there was hardly anything I could do without breaking the CALL core codebase.
Basically, after I'd exhausted all my usual bag of tricks I looked a little closer at the assembly thrown out by the compiler. Maybe there was something that wasn't quite obvious happening in the engine.
.L1031:
leal -72(%ebp), %eax
addl $76, (%eax)
movl -72(%ebp), %eax
movl (%eax), %eax
movl %eax, -2748(%ebp)
jmp .L1194
.L203:
leal -72(%ebp), %eax
addl $76, (%eax)
movl -72(%ebp), %eax
movl (%eax), %eax
movl %eax, -2748(%ebp)
jmp .L1194
....
L1194:
jmp *-2748(%ebp)
As you can clearly see, the jump target is yet another jump instruction. For a pipelined CPU that's really bad news, especially when the jump is so long off. So I wrote up some assembly to remove the double jump and convert into a single one.
#ifdef __i386__
#define ZEND_VM_CONTINUE() do { __asm__ __volatile__ (\
"jmp *%0" \
:: "r" (EX(opline)->handler) ); \
/* just to fool the compiler */ \
goto * ((void **)(EX(opline)->handler)); } while(0)
#else
#define ZEND_VM_CONTINUE() goto *(void**)(EX(opline)->handler)
#endi
So in i386 land the jump is assembly code and marked volatile so that it will not be optimised or rearranged to be more "efficent".
.L1031:
leal -72(%ebp), %eax
addl $76, (%eax)
movl -72(%ebp), %eax
movl (%eax), %eax
#APP
jmp *%eax
#NO_APP
movl -72(%ebp), %eax
movl (%eax), %eax
movl %eax, -2748(%ebp)
jmp .L1194
.L203:
leal -72(%ebp), %eax
addl $76, (%eax)
movl -72(%ebp), %eax
movl (%eax), %eax
#APP
jmp *%eax
#NO_APP
movl -72(%ebp), %eax
movl (%eax), %eax
movl %eax, -2748(%ebp)
jmp .L1194
The compiler requires a goto to actually realize it has to flush all the stack params inside the scope. I've learnt that fact a long time ago trying to do the same for dotgnu's amd64 unroller. Anyway, let's look at the numbers.
Before: After: simple 0.579 simple 0.482 simplecall 0.759 simplecall 0.692 simpleucall 1.193 simpleucall 1.111 simpleudcall 1.409 simpleudcall 1.320 mandel 2.034 mandel 1.830 mandel2 2.551 mandel2 2.227 ackermann(7) 1.438 ackermann(7) 1.638 ary(50000) 0.100 ary(50000) 0.097 ary2(50000) 0.080 ary2(50000) 0.080 ary3(2000) 1.051 ary3(2000) 1.024 fibo(30) 3.914 fibo(30) 3.383 hash1(50000) 0.185 hash1(50000) 0.182 hash2(500) 0.209 hash2(500) 0.198 heapsort(20000) 0.616 heapsort(20000) 0.580 matrix(20) 0.500 matrix(20) 0.481 nestedloop(12) 0.953 nestedloop(12) 0.855 sieve(30) 0.499 sieve(30) 0.494 strcat(200000) 0.079 strcat(200000) 0.074 ------------------------ ------------------------ Total 18.149 Total 16.750
This is in comparison to the default php5 core which takes a pathetic 23.583 to complete the tests. But there's more to the story. If you look carefully, you'll notice that there's a register indirection just before the move. But x86 does support an indirect indexed jump with a zero index.
__asm__ __volatile__ ("jmp *(%0)",:: "r" (&(EX(opline)->handler)));
That generates a nice jmp *(%eax); which is perfect enough for my purpose. Except for the fact that I can see in the assembly, the above fix didn't really do much for performance. For example, look at the following code :-
leal -72(%ebp), %eax
addl $76, (%eax)
#APP
nop
#NO_APP
movl -72(%ebp), %eax
#APP
jmp *(%eax)
#NO_APP
The EAX loader between the two custom asm statements is what I was trying to avoid. But the variable is re-loaded again from stack because there is no register variable cache for the handler pointer. One way around that is to do what pnet did, keep your PC (eqiv of handler var) in a register, preferably EBX and use it directly. The seperation between operands (stack) and operator (handler) makes it hard to optimize both in one go. The opline contains both together making it really really hard to properly speed up.
But there's this thing about me - I'm lazy.
--Captain, we have lost entire left hamster section.
Now, pedal faster.
Last night, I was attempting to build Flubox-0.1.14 on my home amd64 box. After struggling with a couple of errors in src/Resource.hh I managed to get it built with gcc-3.4.2. Now the real bug hunting started in earnest. So consider the following code.
void va_arg_test(const char * pattern, ...)
{
va_list va;
int i = 0;
const char *p;
va_start(va,pattern);
while((p = va_arg(va, char *)) != 0) {
printf("%02d) '%s'\n", ++i, p);
}
va_end(va);
}
int main(int argc, char * argv[])
{
va_arg_test("wvZX", "hello", "world", 0);
}
Now, to the inexperienced eye it might look like perfect working code. But the code above is buggy. If I wanted to really fix it, I'd have to rewrite it so.
va_arg_test("wvZX", "hello", "world", NULL);
The old code pushes 2 pointers and an integer into the stack as variable args, while it reads out 3 pointers inside the loop. In normal x86 land that's not a big deal because pointers are integers and vice versa. But my box is an amd64, there LLP64 holds sway. A pointer is a long long, not just a long. So it reads 32 bits of junk along with the last 0 and goes on reading junk off the stack.
If you'd run my so called buggy code on an amd64, you'd have found that it doesn't actually crash at all. That's where the plot thickens. To understand why it doesn't crash, you have to peer deep into the AMD64 ABI for function calls. As far as I remember, the ABI says that the first 6 arguments can be passed to a function using registers. So the current assembly listing for my code shows up as
movl $0, %ecx
movl $.LC1, %edx
movl $.LC2, %esi
movl $.LC3, %edi
movl $0, %eax
call va_arg_test
But if I increase the arguments to 8 parameters, then the data has to be pushed into the stack to passed around and then you'll note the critical difference in the opcodes between a pointer and integer handling.
movl $0, 16(%rsp)
movq $.LC7, 8(%rsp)
movq $.LC8, (%rsp)
movl $.LC4, %r9d
...
movl $0, %eax
call va_arg_test
As you can see the integer 0 is moved into the stack using the movl while the pointers were moved in using the movq viz long word and quad word. Doing this for varargs on amd64 leaves the rest of the quad word in that stack slot unitialized. Therefore you are not guarunteed a NULL pointer if you read that data out as a char *.
After that was fixed in XmbFontImp.cc, fluxbox started working. God knows how many other places has similar code that will break similarly.
--At this rate you'd be dead and buried before that counter rolls over back to zero.
Better get some exercise if you want to fix it when it happens.
Just got pissed with man pages. The idiotic tool has been pissing me off with a complete inability to scroll to the top or wrap around searches to the top. So I did some digging on how man actually displays the data. Here's a inside view on how the gzipped man pages are displayed on screen and it's an excellent example of the unix way of doing things.
bash$ ps x | grep "/usr/share/man" .... sh -c (cd /usr/share/man && (echo ".pl 1100i"; /usr/bin/gunzip -c '/usr/share/man/man1/seq.1.gz'; echo ".\\\""; echo ".pl \n(nlu+10") | /usr/bin/gtbl | nroff --legacy ISO-8859-1 -man -rLL=77n -rLT=77n 2>/dev/null | /usr/bin/less -iRs)
The man page for man provide yet another peice of the puzzle, where exactly this particular command is pulled from. There's a file called /etc/man.config which specifies where the pager (i.e less, more) command is pulled out of. And the default value was less. Instead of replacing it for the entire system, every user can override it by setting $MANPAGER in their environment. And so I did.
export MANPAGER="col -b | vim -R -c 'set ft=man nomod nolist' -"
Now, everytime I type "man something" I can read the manpage in vim.
--blithwapping (v): Using anything but a hammer to drive a nail into a wall
I don't know if you are even aware of Chris Shiflett's latest injection bug. It was reported in Mysql 5.0 and suddenly every other DB engine writer realized that it was present in almost every one of those. Postgres even churned out an immediate release to fix this particular issue. The blind spot of the whole fiasco has been multibyte encodings whereas the add_slashes is not binary safe. I was lurking in one of the php developer channels listening to exactly how this could've been exploited and it sounded really serious.
So 0x955c is a single SJIS character, when locale is taken into account, it's just a single character. But when you ignore locale and treat it as latin-1 it looks like 0x95 followed by a backslash. So in the php land, instead of treating it as a single character, escapes the backslash giving you a two character string that looks like 0x955c \ . Now you've got a stray slash which can be used as part of a user supplied escape sequence to inject whatever you require into the query data.
After Sara had explained all that, we turned to the quick fixes. Now, let me introduce UTF-8. A closer inspection of the UTF-8 code table and rationale behind contains the following pearl of wisdom - "The remaining bytes in a multi-byte sequence have 10 as their two most significant bits". So if you were using UTF-8 everywhere to handle unicode, it is not possible for a multi-byte character to end with the ordinal value of \ (0x5c). So convert a string to UTF-8 before escaping the backslashes and you're safe from this bug. So practise safe hex and always use UTF-8.
But for me the whole bug had a more hilarious side to it. Yesterday, I got two php server admins to take down talks.php.net (cached). And the reason it was taken down was due to a set of security vulnerabilities in a set of examples attached to a presentation. Authored by, you guessed it, Chris Shiflett.
<g0pz> Derick: but I want to know what exactly is bugging the system <Derick> the apache process don't want to die either <Derick> all are dead now <Derick> let's start again <g0pz> it was probably the one I had attached with gdb <Derick> atleast the site works again <g0pz> Derick: shall I kill it again ? :) <Derick> g0pz: you know how to? <g0pz> edink: http://talks.php.net/presentations/slides/shiflett/ <> oscon2004/php-security/code/shared-filesystem.php?file=/etc/passwd <g0pz> I found this in the access_log !!! <g0pz> Derick: that script is very very scary <g0pz> *please* *please* take it offline ? <edink> bloody hell <Derick> i now wiped all *.php files in shiff's dir <edink> and he now works for omniti? <Derick> yeah :) <g0pz> well, I'd have just put a .htaccess Deny all there <edink> g0pz: rm -rf is more effenctive :) <g0pz> more permanent ? :) <johann__>slides/acc_php/tmp_table.php - sql (union) injection <edink> g0pz: yeah, security risks like that need to be dealt with permanently <g0pz> edink: IMHO, he probably wrote up that demo during the lunch break <> before his presentation <edink> but how did that bring the site down? <Derick> some loop i think <Derick> .htaccess is disabled * Sebastian .oO( And he is an security expert, right? ) <Derick> i don't have the time to deal with this either <edink> yeah ;) <Derick> i'll just turn off talks for now so that somebody can fix it
Somehow it stuck me as ironic that a security expert's own code should help someone read out the /etc/passwd from a publically visible, high traffic server. As Bart Simpson put it - The ironing is delicious.
--The function of the expert is not to be more right than other people,
but to be wrong for more sophisticated reasons.
-- Dr. David Butler
In php5 static variables in functions behave a little differently when the functions are member functions of a class. The problems start when the inheritance starts copying out functions into the child function table hashes. For instance, consider the following bit of code :
<?php
class A {
function f()
{
static $a = 10;
$a++;
echo __CLASS__.": $a\n";
}
}
class B extends A { }
$a = new A();
$b = new B();
$a->f();
$b->f();
?>
Now, I'd assumed that it would obviously produce 11 12 as the output. Sort of ran into this while messing around with the zend_op_array reference counting code. The static members are killed off before the reference is checked.
gopal@knockturn:/tmp$ /opt/php5/bin/php -q test.php A: 11 A: 11
I definitely was slightly freaked and wrote up an almost identical bit of C++ code to just test out my preconceptions about static variables.
#include <stdio.h>
class A
{
public:
void f() {
static int a = 10;
a++;
printf("A: %d\n", a);
}
};
class B : public A {};
int main()
{
A a;
B b;
a.f();
b.f();
}
But static variables inside a function in C++ behave identical to whether it was declared inside a class or outside. There seems to be no special handling for member functions unlike what php shows.
gopal@knockturn:/tmp$ ./static-test A: 11 A: 12
I am not enough of a dynamic language geek to decide which one's the right way to do it. Actually if I really had my way, there wouldn't be any static variables in functions at all. They're actually too much like global variables in terms of life-time.
Anyway, using a class static should make it behave like C++.
--In theory, there is no difference between theory and practice.
In practice, there is.
Last october, Radek Polak suddenly announced that now dotgnu has a debugger. As much as that was good news, it still didn't fit in easily with the current design where the debugger works over the wire. On wire debug protocols are all the rage these days and for good reason, except that a few too many exist in some places. The new debugger backend is checked into Portable Studio SVN for those interested in the nitty gritty details. Here's a sample debug session.
The server is running at port 4571
Waiting for a connection...
Connection accepted
--------------------------------------
Shortcuts for recently used commands
0. watch_method PrintFn
1. unwatch_method PrintFn
2. list_threads
3. unwatch_all
4. stack_trace
5. print_locals
6. dasm
7. watch_location simple.cs 2
8. watch_all
9. watch_method Main
--------------------------------------
> l
<DebuggerResponse>
<Breakpoint Offset="-1">
<Location Linenum="0" Col="0"><SourceFile Filename="" /></Location>
<Member MemberName=".ctor" Owner="$Synthetic.$164">
<MemberSignature Language="ILASM"
Value="public hidebysig specialname rtspecialname
instance void .ctor(int32) runtime managed "/>
<MemberType>Constructor</MemberType>
</Member>
</Breakpoint>
</DebuggerResponse>
> print_locals
<DebuggerResponse>
<LocalVariables>
<LocalVariable Value="10" />
<LocalVariable Value="0" />
<LocalVariable Value="0" />
</LocalVariables>
</DebuggerResponse>
That is the raw debugger protocol dump, now I'll just wait for Radek (or someone else) to slap a pretty UI on top of that. In all probabilty, Portable Studio will let me debug dotgnu code without all the hassles we've been going through for the past few years.
Developer tools are the crack cocaine of the software world. One try and you're hooked.
--Debugging is over when people get tired of doing it.
I've been playing around with Inkscape for nearly ten months and recently sat down to draw the posters for the Yahoo! Bangalore Hack Day. Swaroop has put up photographs of the posters I've drawn. I'm a bit proud of them, mainly because I really can't draw to save my life. So here's the result of about 3 nights of tweaking SVG - with teemus providing real time feedback and spo0nman providing a set of ideas scribbled using gimp.


I'll never be a graphic artist - but at least I can fake it ;)
--Any fool can paint a picture, but it takes a wise person to be able to sell it.
Somebody asked me to explain how the kartwheels engine
hooked into the Mozilla js engine. But I don't have
that code, but I still have code left over from my
previous hacks from sometime before foss.in, when Tarique trolled
about greasmonkey for links.
The hack got dumped because the DOM in
elinks is free'd immediately after rendering and the render
heirarchy is what remains after the first few seconds. But
that code is reincarnated here to serve as a first base
for the average C programmer trying to embed javascript
in his *unthreaded* application  .
.
Basically the embedding API uses two constructs for reentrant code - JSRuntime and JSContext. These hold the equivalent positions as the ILExecEngine and ILExecProcess in dotgnu. Basically, if I wanted to use a single instance to run two scripts without polluting namespaces, I'd use a single runtime and two contexts. After creating these, the task gets easier and easier (you wish !).
declaring a function: All the functions have a bounding object, which for the seemingly unbound ones is the global method. In a browser the global object is the "window". The declaration for the global method is basically cut and paste and very similar to the other class object declarations so I'll just leave it out for now. The functions are declared using JS_DefineFunctions .
static JSFunctionSpec glob_functions[] = {
{"print", Print, 0},
}
JSObject * glob = JS_GetGlobalObject(ctx);
assert(JS_DefineFunctions(ctx, glob, glob_functions) == JS_TRUE);
popping arguments: The arguments are received by the function (which is in C land) as a set of jsval* pointers and an argument count. Each function is assumed to handle its own argument handling, leaving us with the option of handling variable number of arguments. My Print function does just that - printing out all the arguments it received.
JS_STATIC_DLL_CALLBACK(JSBool)
Print(JSContext *cx, JSObject *obj, uintN argc, jsval *argv, jsval *rval)
{
uintN i, n;
JSString *str;
for (i = n = 0; i < argc; i++)
{
str = JS_ValueToString(cx, argv[i]);
if (!str) return JS_FALSE;
fprintf(stdout, "%s%s", i ? " " : "", JS_GetStringBytes(str));
}
fputc('\n', stdout);
return JS_TRUE;
}
declaring objects : Now every object needs a class. More accurately, I haven't figured out how to just construct a simple hash from spidermonkey land. But it suits my purposes to use objects and accessors to implement what I need right now. One of the first things I did in elinks was to put a hook on the <img> element which infact has very little effect on the renderer core. The following code is just pulled out and has the JS_GetPrivate/JS_SetPrivate code removed.
static JSClass image_class = {
"image", JSCLASS_HAS_PRIVATE | JSCLASS_NEW_RESOLVE,
JS_PropertyStub, JS_PropertyStub,
JS_PropertyStub, img_setProperty,
JS_PropertyStub, JS_ResolveStub,
JS_ConvertStub, JS_FinalizeStub
};
static JSBool img_setProperty(JSContext *ctx, JSObject * obj, jsval id,
jsval *vp)
{
char * name = JS_GetStringBytes(JS_ValueToString(ctx, id));
char * value = JS_GetStringBytes(JS_ValueToString(ctx, *vp));
fprintf(stderr, "<image %p>.%s => %s\n", obj, name, value);
return JS_TRUE;
}
Having declared our class, we proceed to write a few lines of code to construct a simple object from the class and attach our bound methods to the object. Technically, I can attach the methods to a prototype and provide that to the class definition. But this way seemed easier while I was at it than go through a hierarchy of prototype hashes while debugging method call resolution.
JS_STATIC_DLL_CALLBACK(JSBool)
img_Show(JSContext *cx, JSObject *obj, uintN argc, jsval *argv, jsval *rval)
{
JSBool show;
if(argc == 0) return JS_FALSE;
assert(JS_ValueToBoolean(cx, argv[0], &show) == JS_TRUE);
fprintf(stdout, "<image %p>.show(%s)\n",obj, show ? "TRUE" : "FALSE");
return JS_TRUE;
}
static JSFunctionSpec img_functions[] = {
{"show", img_Show, 0},
};
int defineImage(JSContext * ctx, const char * id)
{
JSBool ok;
JSObject * img = JS_DefineObject(ctx, JS_GetGlobalObject(ctx),
id, &image_class,
NULL, 0);
ok = JS_DefineFunctions(ctx, img, img_functions);
return (img != NULL);
}
compiling & running js: The easiest way to run the javascript is to use the following two step approach - JS_CompileFileHandleForPrincipals and JS_ExecuteScript. The first function accepts a FILE * and gives you a JSScript* and the second one obviously executes the script you just compiled. With that, your js engine embedding is complete. Oh, and don't forget to call defineImage while parsing the DOM tree.
There are a lot more nuances in there, like GC rooting. The engine GC does not scan your address space and cannot preserve objects which are only referred from your code space. To work around this, you could create a GC root by hand and attach your objects there so that you can prevent them from being GC'd till you're done with it. But remember to just cleanup the GC root when you're done with the object - this works sort of like a pool, only the crashes might be a few minutes later instead of immediately after you free the root (FUN !! ).
But none of them really matter to a newbie taking a few baby steps into VM embedding land and I didn't really do it proper when I did kartwheels either. Matters not, here's the sample code for people to play around with. Also take a good long look at spidermonkey api docs and the MDC Javascript Embedder's guide - they basically cover all my code, though in a different level of detail.
[gopal@phoenix spidermonkey]$ make gcc -ggdb -L/usr/lib64/mozilla-1.7.3 .... testjs.c -o testjs [gopal@phoenix spidermonkey]$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:. [gopal@phoenix spidermonkey]$ ./testjs hello.js Hello ! <image 0x50f8c0>.src => /tmp/x.png <image 0x50f8c0>.show(TRUE) <image 0x50f8c0>.show(FALSE
That's basically how it all begins and then after you've been debugging for four hours syncing/locking JS threads with the gtk+ event-loop ... Zzzz
--The more I want to get something done, the less I call it work.
-- Richard Bach
Today was Yahoo! Bangalore's hack day. After having literally killed myself debugging spidermonkey js magic for an entire night, this was my chance to actually let the world see my cute little application run real Konfabulator widgets. The hack itself isn't too spectacuar, it merely combines some widely available libraries, spidermonkey, zziplib, libgdk, curl and libxml2, to run the widgets. Unlike all the efforts of dotgnu, there was no complicated binary formats, nor were there any limitations of performance. Basically - it just worked.
So after pulling in a few widgets and throwing out all the animation and other eyecandy stuff out, I was able to get a decent group of widgets working. The most spectacular of which was the Yahoo! News Reader. Here's a screenshot with corresponding clickys for the widget sources.

But just like all my other efforts, this project was also DOOMED. And just like all the other screwups that punctuate my life I have nobody but to blame but me. I did a hurried demo of the application using a windows machine via VNC. I was probably too negative (as teemus pointed out) or maybe I was all hung over from not sleeping, it was a lukewarm performance at best. I expected the code to speak for itself and I failed to impress anyone with the potential of this hack.
For a few moments, I felt crushed. From that point onwards, there was only one path to closure for the whole project. I had to throw away all that code and keep walking without a glance back. I know I have the strength to do exactly that and do it without flinching. And I did it.

Even if I'd kept this codebase, the world could've never seen it opensourced as it is a competing with a Yahoo! product. But the code isn't lost to the world completely. Two people mailed me asking for the code and I sent them the code as an attachment. But for their mailboxes, the world has no trace of kartwheels now.
I do not know why, but I feel liberated.
--"Plan to throw one away. You will anyway."
-- Fred Brooks, The Mythical Man Month
When I first read about Greasemonkey, I never realized how much power exactly that added to the hands of the common browser. Gone are the days when you had no choice but to put up with whatever's served. So when I noticed that planet.foss.in had stopped showing images with some css, I did what every greasmonkey aware user does - wrote an un-hider for images. I just went a step further (thanks in no amount to Kushal's latest huge images) and forced all images to be < 480px in width.
--Dinosaurs aren't extinct. They've just learned to hide better.
FOSS spawns a huge number of applications, anyone who has seen freshmeat can confirm that. Very few of them really reach usability and even fewer are well maintained. So here are some I found lying around in my own harddisk, along with the rpms mirror I pulled out sometime back.
Ever since I saw XGL (more correctly compiz) doing extra magic during the kororaa demo at NITC, I've been wanting to try it out. But this one was a surprise - 3ddesktop. It is basically a 3d desktop switcher that could be hacked around to work like XGL has - but minus the actual X updates across the multiple faces.
[gopal@phoenix ~]$ 3ddesk --acquire=1 [gopal@phoenix ~]$ 3ddesk --mode=cylinder --nozoom --goto=2
It is the most awesome thing I've ever seen work out of the box. Even without restarting X11, it just started working. The screenshot is of carousel mode with zoom enabled. You can see my four desktops and the various things on them. OpenGL rules.
The night sky in Bangalore is orange. We have too many glowing streetlights to actually see the sky. While I was in NZ, I remember walking around in the garden at 2 AM looking at the stars I've never seen before. I've marked out the Southern Cross in Celestia and now I can watch them anytime I want. Anyway, a set of spots with no connections hardly makes any sense to the average viewer. Then there's that small blue planet that is hardly even in the middle of nowhere that we are quite interested in.
But before I started bitching about the lack of marked constellations in Celestia, I ran into something that's even more awesome. This one is a virtual planetarium on your desktop - Stellarium. This thing literally blew my mind away. There is no other program I've ever seen that makes me want to plonk down hard cash. If I ever go to a college to talk again about the coolness of software, I am sure as hell going to demo this particular application. Head and shoulders about the rest, that's what this one is. This is a bloody video game, that is what it is. There is even a windows build for it.
All the following images are screenshots captured from Stellarium. If I'd pulled the ones without markings, you could misunderstand them for real photographs. If you don't believe me, look at the bigger versions.






I don't know how many of you have played an old DOS game called Xargon. But I am pretty sure you guys have seen one of the Mario series at least. So, supertux is a side scroller of the very same sort. Except for the lame save file style - which is a plain-text lisp macro file, I love the game. Maybe I might love it better because of the lame save file *wink* *wink*.


Then floated before my very eyes, something that was even more annoying than anything before (and probably after). Something that burns CPU just to render on screen and even more because of all the composition on the backbuffer. I give you xpenguins. They even have themes, like the Simpsons with Bart & Lisa. The most awesome part is when the penguins fall too far - they die with a lot of gruesome blood and fly away as a angels. I literally died laughing when Bart mooned standing over a root terminal.
There are serious tools in there as well, like redir. This is a port deflector which accepts connections and forwards them elsewhere. Looks to be a lot cleaner than using netcat/ssh for the job as I've always done. But yeah, those are almost on every *NIX box - this might not be. Or hping which can finally send SYN pings which aren't blocked by most boxes. Technically you can take down entire blocks of webservers using that simple tool - not Yahoo!'s or any decent company's servers, but not everyone knows what Accept Buffering means. For the really paranoid security dudes, there's the knock which lets you script up your port knocking. How about if I hit 3333 and 6666 twice within 10 seconds, the firewall lowers the connections to ssh-22 for next minute - well, then I'd really need knock around or I'll be writing LOTs of code in the link layer to detect hits on closed ports. And ssh proxy-command has the ideal thing for it - nc host port1 ; nc host port2 ; nc host 22 .
Also when you walk around a wifi network, you can't do without kismet or in a pinch, ssidsniff. Last cool toy around is the fakeap which lets you fake the existence of hundreds of 802.11 accesspoints with a few thousand beacon frames. I wonder what would happen to the poor guy who tries this at a conference - killed by a thousand laptop blows ? Or maybe run driftnet on a host with lots of traffic and see how many naughty pictures people browse.
It is already the next day now and I still haven't played around with torcs, dircproxy or qdvdauthor. More importantly, I haven't really tried out all the network tools that are so important to my basic mode of operation. Maybe sometime later.
--We are all in the gutter, but some of us are looking at the stars.
-- Oscar Wilde
Some of the world prefers to know their destiny (if there is such a thing) from tea leaves. I, for one, prefer to drive mine using coffee beans and chaos (code and chocolate optional). Needless to say, I sat down at my box planning to write something totally random, pointless and useful only to my curiousity - as befitting the first of mad new year's. On a side note, did they call all of us Indians who celeberated new years last week fools ? Anyway, I wrote something that would read RPM .hdr files as dumped on my disk by yum. The docs were pretty useless and so was all the samples on my box - but I read through the pullheaders.py inside yum and discovered most of the secret calls used.
As it turns out, there is no function around which will accept a filename for a .hdr file. The closest I found was rpm.headerLoad which seemed to accept a string and then complain about a bad header. The code for rpmlib is pretty heavily documented though completely useless for my particular purpose. After I discovered the secret Gzip calls inside the old rpmutils, I began to suspect what headerLoad actually takes in might be a gzip decompressed buffer of data rather than just a filename. From that point onwards it was a peice of cake.
import rpm,gzip hdr = rpm.headerLoad(gzip.open(f).read()) name = hdr[rpm.RPMTAG_NAME] description = hdr[rpm.RPMTAG_DESCRIPTION] summary = hdr[rpm.RPMTAG_SUMMARY]
To test this code properly, I started pushing in all the headers in my dag repo mirror I have at home. I found quite a few interesting applications once I started reading the HTML output of this program. More on that later.
--Make sure every module hides something.
- The Elements of Programming Style (Kernighan & Plaugher)
You see all these links around with ymsgr: in them. Well, I was tired of cut pasting those and then removing all the url and SendIM crap. gaim-remote supports AIM urls out of the box, mostly. I wondered how hard Yahoo! would be - it turned out to be a peice of cake.
You can find my patch - remote.c.patch. It is basically something any idiot could've written. Here's most of the code :-
/* ymsgr:SendIM?*/ else if (!g_ascii_strncasecmp(uri, "ymsgr:SendIM?", strlen("ymsgr:SendIM?"))) { char *who; char *msg; GaimConversation *c; uri = uri + strlen("ymsgr:SendIM?"); who = g_strdup(uri); /* we don't want to implement messages, dude */ if((msg = strchr(who, '&')) != NULL) { *msg = '\0'; } c = gaim_conversation_new(GAIM_CONV_IM, gc->account, who); g_free(who); }
Was that simple or what ? Sadly the gaim-remote plugin is no longer in cvs. So there's no point in submitting a patch upstream.
firefox/thunderbird support: . First you need to add two entries to your about:config. The first is a string entry network.protocol-handler.app.ymsgr and it contains /usr/local/bin/ymsgr-launch and the other one is a boolean entry named network.protocol-handler.expose.ymsgr with true. The ymsgr-launch is basically an executable shell script with the following.
#!/bin/sh gaim-remote uri $1
At this point, both the ymsgr:SendIM and ymsgr:AddFriend work nicely. Click, click and click.
--I waited and waited and when no message came I knew it must be from you.
This is not an admission that's going to cost me much - I love xterms. If you peek into my desktop at any random time, you'll find a bunch of xterms all ssh-ed into different boxes. And you'd notice one thing, they are all black and with green text scrolling down it. For some Matrix fans here, that'd sound like the only way to watch compiling code scroll by. Other than the nostalgic rush of blinking green monochrome monitors, there is a more pragmatic reason behind this. I just find it easier to read green than white text - it seems to have more contrast than white on black, as strange as that might sound.
So all my xterms are green on black, but that's because the shortcut configured spawns them with xterm -fg green -bg black. But I've got a few scripts which spawn xterms in a loop and I really didn't want to pass these args there directly. Before I go deep into xterm land, let me explain why exactly you'd need that.
APACHE_CHILDREN=`ps fax | grep "\_ /usr/sbin/httpd" | cut -f 2 -d' '`
for pid in $APACHE_CHILDREN; do
xterm -e "gdb --pid=$pid -x c.gdb" &
done
That is what I use to debug multiple apache children for APC. It is a pretty straight forward script, except that I run it on different boxes. Now, I want to make the background and foreground colour configured per user+box rather than hard-code it in a script. The man page has absolutely no information on this particular subject - merely mentions that /usr/lib/X11/app-defaults/XTerm-color is where the system wide configuration lives.
A further read through shows that all such X resources defined can be overriden using ~/.Xdefaults file. But that didn't work. This is exactly where users stop and developers continue probing. One of my favourite tools for finding configuration files read by an app is strace.
[gopal@phoenix ~]$ strace -e open xterm 2>&1 | grep "gopal"
open("/home/gopal/.Xauthority", O_RDONLY) = 4
open("/home/gopal/.Xdefaults-phoenix", O_RDONLY) = -1 ENOENT
....
So in this version of xterm, the code hits the ~/.Xdefaults-hostname file to pick up the configuration values and then it all pretty much fell into place - here's what that file had to contain.
*VT100*foreground: green *VT100*background: black
Now, to go and play around with a few more interesting xterm configuration parameters - *saveLines and *VT100.utf8Fonts.font. I'm probably reinventing a lot of wheels and documentation here, but as long as it is fun ...
--He is a man capable of turning any colour into grey.
-- John LeCarre
the problem: If you are a C programmer and I mean a really serious C programmer, you must've had to debug at least one memory leak bug in your life. Unless you built something like a CGI script which got torn down after seconds of existence, your patience must've cracked trying to figure out what is exactly slowly eating into your memory space. Even worse, after you found the exact chunk size that was leaking periodically, you might have no way of actually debugging where it leaked. Sooner or later, you learnt about electricfence and more importantly dmalloc. And of course, of valgrind - the holy grail of memory overwrite debugging.
less data, more info: These tools show a big picture view of the process, which meant that you got to see all the leaks everywhere. If you are debugging something huge like evolution, thunderbird or firefox - you don't want to see the entire leak listing because the data structures needed to keep that info outside the process itself is huge. Plan for a couple of GBs if you want to properly run valgrind on such a codebase. The other solution is to put macros everywhere to relay your file name and line numbers to your data structure classes so that you can figure out that the leak apparently in hash.c or string.c is really in prepare_for_cache_premature_optimisation.c.
recompile all strategies: This strategy also fails when you start passing around function pointers. Unless your function pointer prototype changes along with the debug mode, you cannot use that. If you are building a small extension to a big project like php, you do not have the luxury of testing out some two thousand lines of your code on production with a debug mode. That is when you try to figure out how to pass data without adding extra parameters to your function signatures. Using global variables like FFCall trampolines do is not quite the thread safe way.
gcc local functions: There are functions which are local to another function. Try compiling the following code in your gcc.
typedef int (*intfun)(int i);
intfun make_adder(int i)
{
int add(int k)
{
return (i+k);
}
return add;
}
int main()
{
intfun foo;
foo = make_adder(2);
printf("%d\n", foo(3));
return 0;
}
no, not that way: Even though it might look like a closure to the inexperienced eye, a quick run of the code will tell you that it doesn't work the way you'd have expected it to work. So I decided to quickly hack up a simple closure wrapper for a function by dynamically generating code.
With the help of x86_codegen.h and a rough understanding of x86 call frames, I started to hack this out. This is how the first cut looked like.
malloc_fun_t make_closure(malloc_fun_t original,
const char * filename, int line)
{
byte * code = malloc(4096);
byte * method = code;
x86_push_reg(code, X86_EBP);
x86_mov_reg_reg(code, X86_EBP, X86_ESP, 4);
/* add 8 (two words) to size */
x86_alu_membase_imm(code, X86_ADD, X86_EBP, 8, 8);
/* frame for next function */
x86_alu_reg_imm(code, X86_SUB, X86_ESP, 12);
/* push size */
x86_push_membase(code, X86_EBP, 0x8);
x86_call_code(code, original);
/* pop frame */
x86_alu_reg_imm(code, X86_ADD, X86_ESP, 12);
/* return value in eax, push in data */
x86_mov_membase_imm(code, X86_EAX, 0, (int )filename, 4);
x86_mov_membase_imm(code, X86_EAX, 4, (int)line, 4);
x86_alu_reg_imm(code, X86_ADD, X86_EAX, 8);
x86_leave(code);
x86_ret(code);
return method;
}
But very quickly, I realized that this code segvs on some libc versions while running perfectly fine on all the others. Turns out that with security patches turned on, you cannot run code off memory you allocated using malloc. But it proved to have a simple work around - mmap();
void *allocate_executable_mem(size_t size)
{
static int zero_fd = -1;
void * addr;
if(zero_fd == -1)
{
/* thread safety is for another day */
zero_fd = open("/dev/zero", O_RDWR, 0);
}
addr = mmap(NULL, size, PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_SHARED | MAP_ANON, zero_fd, 0);
return addr;
}
That PROT_EXEC did the trick and the memory was now writeable and executable from userland. Then I added a couple more lines of code to ensure that I can distinguish a closure wrapped call from a standard gcc compiled code with a signature magic embedded in the binary code. And wrote some code to jump over it while executing the method.
target = code;
x86_jump8(code, 0);
/* magic to identify closures */
*(code++) = 0x42;
*(code++) = 0x13;
*(code++) = 0x37;
*(code++) = 0x42;
x86_patch(target, code);
Now, I had a function which looked like malloc for anyone calling it, but could relay information about its source line and file in -1 and -2 offsets from start of the returned block. Look at asm-cl.c.
73 malloc_fun_t f = make_closure(malloc, __FILE__, __LINE__); (gdb) x/8i f 0xf1a000: push %ebp 0xf1a001: mov %esp,%ebp 0xf1a003: jmp 0xf1a009 0xf1a005: 0xf1a006: 0xf1a008: 0xf1a009: addl $0x8,0x8(%ebp) 0xf1a00d: sub $0xc,%esp 0xf1a010: pushl 0x8(%ebp) (gdb) c Continuing. 0x8a9f010 traced to asm-cl.c:73 0x8a9f028 traced to asm-cl.c:74
People under-estimate what can be done with C when they say that " I know C ". I'm sad to say that there are whole cookie cutter assembly lines of colleges churning out students who won't appreciate such hacks which subvert the entire meaning of function pointers and take them a step closer to understanding what really happens. The urge to take things apart and see what they are made of is a basic enough human trait. Too little of it bubbles through all the exams and internals into real appreciation for the inner wheels of such otherwise useless magic tricks.
There's only one word to describe the above code - CRAZY. I can't believe I sat down and wrote this.
--You may be right, I may be crazy,
But it just may be a lunatic you're looking for!
So there, I go from nobody to being lead developer of APC - it's official, there's no escape. As the commit message clearly says - the folks I have tricked into helping out. By the way, APC 3.0.10 was just released a few hours ago. Imagine two releases in the space of barely 7 days - 3.0.9 was on 4th.
Anyway, I tried to commit something today morning. Basically, it is a fix to the default arg array problems that I've run into twice. Still don't have a reliable test case, but a long drawn chase with gdb showed what was actually the segv'ing data structure. The zval in the constant array was being pulled around and modified in the php engine land. Somewhere the multiple modifications of the shared memory with no locks was ending up in an inconsistent state and the whole shebang goes for a toss. Fix was to just chuck the dangerous bits into the local memory and just let the engine do what it wants.
**** Access denied: insufficient karma (gopalv|pecl/apc) cvs commit: Pre-commit check failed
Anyway, that was quickly resolved on irc and I got some karma (whatever that really means) and I was able to push in a huge merged patch (+832, -316) from HEAD into INH_FIX branch of apc. Thus, my first commit rolls into CVS - #5423. And hopefully that should break a few things here and there - can't make an omlette without breaking eggs.
--"But the important thing is persistence."
-- Calvin trying to juggle eggs
Last night, was an all nighter. I stayed up to hack out some javascript code for yahoo!. In the middle of all that, something new came up - bug #7070. You can read the bug report or you could see what happened on IRC. All this is leading up to something very important, at least to me, so read on.
<edink> Rasmus: commenting out my_fetch_global_vars() and having auto_globals_jit = off
makes apc work on windows
<Rasmus> edink: could you add that to the test case?
<Rasmus> I'm busy breaking apc further
<edink> I'll add comment to #7070
<Rasmus> thanks
<Rasmus> g0pz: edink updated bug 7070
<edink> g0pz: seems that calling zend_is_auto_global() with any value from apc_copy_function_for_execution()
crashes the thing on windows
Ok, so I had a good long long look at the code and started guessing what went wrong. There's one thing I still don't understand about Zend engine - how does the TSRM stuff works. So following the path of ancestors, who relied on the dark and mysterious and of course, mostly unknown powers of evil to explain bad things happening to good people, I too blamed the unknown.
<g0pz> edink: reall weird
<edink> g0pz: yeah
<g0pz> has something to do with tsrm ?
<edink> g0pz: i cannot tell if its tsrm related
<g0pz> because that looks like a bad address there in the tsrm ptr ?
<g0pz> 0x00d5b3f6 seems to be a little on the low side
<g0pz> sort of makes sense
<g0pz> as the apc_copy_function_for_execution_ex is passed as ht_copy_fun_t to copy_hashtable
<g0pz> which just calls the apc_copy_function_for_execution_ex with 4 args
<g0pz> apc_compile.c:926 needs to be fixed to pass the thread safety macros ?
<g0pz> *but* I cannot test anything I fix and neither do I have any idea what any TSRM macro means
<g0pz> so help !!! :)
<Rasmus> TSRM just wraps all the globals in a struct
<edink> g0pz: its just passing void ***tsrm_ls around
<g0pz> so just a TSRMLS_FETCH() in scope is enough ?
<SaraMG> g0pz: You don't need to understand TSRM.... TSRM understands you
<g0pz> SaraMG: in soviet russia ...
<SaraMG> >exactly<
<SaraMG> Now you're getting it
<g0pz> edink: as much as I'd like to help you, this thing needs a professional :)
<g0pz> ok, here's how you fix it :)
<Rasmus> ctrl-alt-del <insert Ubuntu cd>
<g0pz> remove the TSRMLS_DC in apc_copy_function_for_execution_ex
<edink> so your func arglist should have TSRMLS_D (no other args) or TSRMLS_DC (other args) in function definition and
TSRMLS_C or TSRMLS_CC when calling it
<g0pz> and add a TSRMLS_FETCH(); as the first statment in that function
<g0pz> now rebuild and hope it works
<SaraMG> *ick*
<edink> g0pz: TSRMLS_FETCH(); cannot be used if you have TSRMLS_D(C) in function declaration
<g0pz> according to a significant proportion of my brain cells, that is how that could be fixed :)
<g0pz> remove the declaration
<g0pz> you're anyway passing stack junk there
<g0pz> the pointer you got was the apc_php_malloc in place of tsrm_ls
<SaraMG> Ah, yes
<SaraMG> Didn't realize that proto had to conform to a callback definition
<g0pz> SaraMG: the shocking part is that it doesn't
<SaraMG> The callback typedef being (Bucket*,va_list)
<g0pz> that's the check, if I'm not wrong ?
<SaraMG> (void*, void*, apc_malloc_t, apc_free_t)
<Rasmus> hey hey, no peeking under the skirts unless you are going to dig in and fix stuff
<SaraMG> apc_copy_function_for_execution_ex looks NOTHING like the callback's typdef
<SaraMG> Like, not even close
<Rasmus> details ;)
<edink> :)
So, finally I still need to get the other guy to build and test it. Of course, the correctness of the patch has been verified in theory - it was still upto someone to figure out whether that was the only problem in the mix.
<g0pz> edink: don't just stand there, make the changes and rebuild :)
<edink> g0pz: made too many changes to my sources :)
<g0pz> this is just one more :)
<SaraMG> g0pz: So yeah, nix the _DC, use _FETCH, but also add some dummies to that declaration
so it fits the calling semantics
<g0pz> SaraMG: I haven't got commits
<SaraMG> oh.... who are you again?
<edink> Rasmus: just make him an accout :)
<Rasmus> gah, just fill in your username and password
<Rasmus> and garbage in the description field
<Rasmus> those warnings don't apply to people who understand the guts of the engine
<g0pz> tinker with != understand
<Rasmus> close enough
As usualy, we get into optimisations and all that... before it is actually tested.
<edink> g0pz: are you not checking every var if it's an autoglobal? <g0pz> edink: if there's a better way, I'd love to know about it :) <g0pz> because that's what the fetch_simple_variable_ex in zend_compile.c does <g0pz> of course, I could optimize easily <g0pz> with an if(name[0] == '_') :) <edink> g0pz: is the sole purpose of it to load superglobals when jit is on? <g0pz> yes
Finally, the bug is closed - in less than a couple of hours after I saw the bug report.
<g0pz> edink: with that fix, does APC work ? <edink> g0pz: yeah, like a charm <edink> let's see what Rasmus broke :) <edink> well, it compiles :) <Rasmus> everything most likely
End result was that I got commit access to PHP CVS. I am now gopalv of the php - Resistance is Futile. I am yet to be marked as the maintainer of anything, so I'm still in the zone where everything's convenient but nothing really bugs you. Haven't checked in anything yet. That's for a day when I am actually sane and not hopped up on coffee.
Look ma, I'm a php dev :)
--It is not doing the thing we like to do, but liking the thing we have to do, that makes life blessed.
-- Goethe
Halfway through debugging APC last night, I started to get seriously bored with the complete lack of success I was having. So I just kicked back and implemented a new feature for pnet. So far pnet's System.IO.Ports implementation has support for regular serial ports, USB ports and Infrared ports - I wanted it to work with bluetooth. For no good reason, the thought popped into my head - backup my phone numbers with a program.
So I started to recall all the AT commands I'd studied so hard while doing mobile phone testing in Wipro. I didn't have a document for GSM AT commands, neither was I sure how to set up a serial simulation via bluetooth. I cheated a bit by doing a strings libgnokii.so | grep "^AT" but I knew what those commands did. After starting the bluetooth daemon, I discovered that hciconfig/hciattach is *NOT* the tool to attach stuff to hci0. The point to note is that you need to know the bdaddr of the phone you want to hook into.
[root@phoenix ~]# rfcomm -i hci0 connect rfcomm0 00:13:70:C3:AA:7A Connected /dev/rfcomm0 to 00:13:70:C3:AA:7A on channel 1 Press CTRL-C for hangup
Now this is what happens when I give rfcomm0 as the resource in pnet's System.IO.Ports implementation.
Uncaught exception: System.ArgumentException: Arg_PortName
Parameter name: value
at System.IO.Ports.SerialPort.set_PortName(String) in ./IO/Ports/SerialPort.cs:574
at System.IO.Ports.SerialPort..ctor(String, Int32, Parity, Int32, StopBits)
at System.IO.Ports.SerialPort..ctor(String, Int32)
at Phonebooker..ctor(String) in phonebooker.cs:52
at Driver.Main(String[]) in phonebooker.cs:22
Because the terminal I/O device should work with the same API no matter whether it is USB, bluetooth or regular serial ports, there was no real change to the entire code to make it work. Let's just say that it just works and leave it at that.
Then it was smooth sailing to write a small app which would read/write data from the serial port. Essentially the code looks something like the following.
port.Write(command+"\r");
while(port.BytesToRead > 0)
{
String line = port.ReadLine();
if(line.StartsWith("ERROR") ||
line.StartsWith("OK"))
{
break;
}
}
With these four AT commands
- AT+CSCS='8859-1'
- AT+CPBS
- AT+CPBR?
- AT+CPBR=n
Just a quick reminder, you need the latest CVS head code of pnet and pnetlib to test this toy out :)
--If you find a solution and become attached to it, the solution may become your next problem.