This is very definitely not about computer monitors. It is a story about data hashing, distribution and indeed re-distribution - about divisors, primes and more than all of that, downtime & costs.
In all honesty, I'm just posting a conversation from a coffee break almost two years ago (and some context to frame it). I'm writing this down now because it has reached the edge of my memory and is about to fall off.
One day, Prakash in the middle of coffee started to talk about the pains that powers of two cause. I assume, it was because one of the membase clusters (now called zBase) was running out of capacity and needed to be doubled in size.
Doubling in size was the only way our clusters grew, which was all well & good when the product was on its way up. It means you can double in size rather rapidly and without any real downtime. But it does cost a lot of money to keep doing after the first or second rehashing. Doubling made even more sense in a master-slave setup because the old cluster became the new masters and dropped half the data each, which would then be caught up by a new array of slaves which meant it would happen without any downtime for data copying and was a nearly no-risk operation.
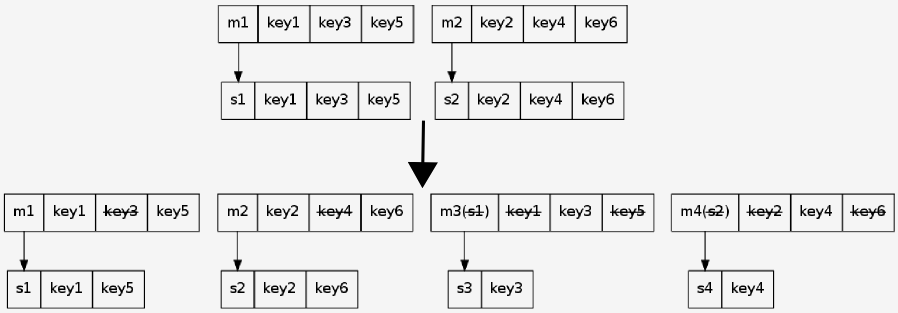
This is relatively straight-forward, because the masters only have key invalidations happening during the re-shard. No data actually moves between masters during the reshard. This is brilliant because a few seconds after you flip the switch, the master array is ready to update and the slaves have a few minutes to catch up. But this is very expensive. Say, you had a 4 node cluster serving out data and eventually node1 runs out of space, then you need to add 4 more extra servers where otherwise only 2 would have been sufficient.
But this is primarily a one-way street. You cannot shrink a server cluster to half its size by this method.
Most startups never need to do that - but this kind of trickery needs to be done to optimize costs in a more mature product. And more relevantly, doubling a cluster to go from 8 to 16 to fix one node that's going out of capacity is so wasteful. If you are prepared to move a lot of data around, you don't necessarily need to double it - but that's the question, the downtime involved in moving the data is usually too much to justify that approach - but at least some of the data moving problems can be bypassed by more intelligent hash partitioning.
The most common hash partitioning method used is a modulo of the hash. Where you take the hash value and % by the number of servers to end up with a server where the data resides. But this has catastrophic consequences when rehashing data across multiple machines. Let us run through the simple scenario of data distributed across 10 machines and adding a 11th machine. So if we follow the hashing algorithms' approach, the only data that would sit still would be items with hash keys which are a multiple of both 10 and 11. For a uniform distribution of data that would approx 0.9% of the data.
Or in other words, with such a stupid hash partitioning mechanism, you'll end up moving 99.1% of data around to bring the cluster to order. So someone was bound to invent a method to work around the doubling problem.
When I was in Yahoo!, I ran into one of the most brilliant solutions to this problem. A mathematical, clean solution - but one which I notice hasn't even been patented. This is somewhat sad, but it shouldn't be lost to the world because it hasn't been published. Basically, it is a hash based solution that outputs a partition id instead of a hash value - basically, when you move up from a 10 node to 11 node cluster, the data only gets moved from all 10 nodes to the 11th node. And with a uniform distribution, each node only loses 10% of data.
There are tons of examples of this approach of consistent hashing, the easiest to use would be the Ketama hash. Or if you care about its origin story, you can see the genesis of this idea elsewhere. But the trouble really is that even with a consistent hash, you'll be moving around individual keys and value pairs to balance your data out. And there was no real clean way to drop data from the machine quickly without going through everything.
As with the revolution pallets caused in warehousing and containers did for shipping (or Quantum theory for physics), the idea of putting data into indivisble containers was the solution. On top of that, having partitioning be independent of machines was a rather easy way out of this particular problem in membase. Basically, bucket the data into a fixed number of partitions independently of actual machine count and then have a second order lookup map which actually tells you where that particular bucket is residing. This would be catastrophic if the clients went out of sync in this mechanism - but all a server had to do was say "Not Mine" when it sees an update or get to the wrong bucket. The client could then refresh the 2nd order mapping lazily without having to get a push update for each reconfiguration of the servers.
Since you move buckets between machines instead of keys and values, it is easy to proxy all updates to a given server into another with a filter on the bucket id (instead of failing - the failure is triggered after the move is finalized), avoiding downtime during the rehash. And you can just drop off the hash for the bucket once it has moved all data from the current machine to another. The locking, deallocation and movement of data now happens in a larger chunk as single transaction - a break in transaction does not leave either side in an inconsistent state. Just drop that vbucket in destination, pick another destination and serialize the in-mem hash for that vbucket for streaming it over.
In some human way, knowing which of those buckets have data/key-space/traffic allows a fairly involved user to actually micro-manage the resharding. And ideally, you can reshard down into a smaller cluster with this approach faster by hand than you can with the ketama, which is likely to make you go nuts since it is a spectrum of keys instead of being wrapped bundles. It is far easier to write a packing algorithm in 2 dimensions with such "rectangular" blocks - x being data size and y being traffic.
Now is when things start to get really interesting, from the Prakash angle. Almost everybody uses a power of 2 as number of these buckets. I remember that membase used to use 1024 by default and I talked to people at Aerospike recently, where they use the last 12 bits of the hash to determine virtual buckets (for the innumerate that is 4096 buckets). Now there is no fair way to distribute these numbers fairly across server counts, naively. According to Prakash, a number like 1440 would've been far nicer. And I did some grade school math to explore that. Basically, the number of fair distribution values below 1000.
1440 : [1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 18, 20, 24, 30, 32, 36, 40, 45, 48, 60, 72, 80, 90, 96, 120, 144, 160, 180, 240, 288, 360, 480, 720] 1024 : [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
In essence, 1024 has 10 divisors and 1440 has 35. In the 1440 case there are 3x number of possible fair distributions of uniform data than in the 1024 case. The scenario is even better when you look at the small digit numbers in the distribution. The first 10 numbers for 1440 are 1, 2, 3, 4, 5, 6, 8, 9, 10, 12. All of which are fair configurations of bucket distributions, where as the 1024 case jumps straight from 8 to 16.
The real commentary here is on the lack of magic in 1024 (and 4096). Also slightly about people who pick prime numbers in this scenario - they work better for some key distributions, but lack the divisibility (duh!) that simplifies the distribution. This number choice is something you have to live with once you pick it, because changing it requires as massive a data movement as the original modulo distribution (because let's face it, the vbucket is a modulo distribution, with modulo picking the vbucket). And for those who picked a power of 2 already, I have to say that it is possible to acheive an ideal distribution of data/traffic irrespective of the actual number of vbuckets. When a server in a group runs out of capacity, just move the highest capacity vbucket in it out onto a new node. It is that simple - the default number only sucks in scenarios of uniform distribution and uniform traffic.
1024's just an imperfect number which will work for you in an imperfect world. Which I am told is often the case.
--There is no safety in numbers, or in anything else.
-- James Thurber
Divide and conquer. That's how the web's scaling problems have always been solved.
And the tier scales out horizontally for a while. You scale the tiers and everything works. But sooner or later you end up with a different problem - latency. The system gets choked out with the interconnects, but the magnitude of the problem is just mind boggling.
Let's take a random example - imagine about 500 memcached servers, 1000 web nodes and 64 processes on each node. Simple back of the envelope math turns it into 32 million persistent connections going on at any given time. But I'm assuming the worst-case scenario - only because that's what's in production in most places.
The real problem is that the preferred scale-out approach for a web tier is a round-robin or least-connection based fair distribution of requests. That works great for read-heavy throughputs where the key distribution is not tied to a user session. But if you ended up with a scenario where you are operating on only one user's data per-request, the wastefulness of this scenario starts to become evident.
What I really want is to pick a web-node which is currently optimal for this particular user's request. The traditional approach is to pick a node and route all subsequent requests to the particular node and hope that I can do at least a few stale reads off the local cache there. We want to go further and pick an optimal web node (network-wise) for this user session. Since the data layer gets dynamically rebalanced and failed nodes get replaced, the mapping is by no means static. Not only is that an issue, strict pinning might cause a hotspot of web activity might bring down a web server.
The solution is to repurpose stateless user pinning as used by HAProxy to let the web tier rebalance requests as it pleases. We plan on hijacking the cookie mechanisms in haproxy and setting the cookies from the webservers themselves instead of injecting it from the proxy.
Here's how my haproxy.cfg looks at the moment
backend app balance roundrobin cookie SERVERID indirect preserve server app1 127.0.0.1:80 cookie app1 maxconn 32 server app2 127.0.0.2:80 cookie app2 maxconn 32 server app3 127.0.0.3:80 cookie app2 maxconn 32
That's pretty much the complicated part. What remains to be done is merely the php code to set the cookie. The following code is on each app node (so that "app2" can set-cookie as "app3" if needed).
$h = crc32("$uid:blob"); # same used for memcache key
$servers = $optimal_server[($h % $shard_count)];
shuffle($servers);
$s = $servers[0];
header("Set-Cookie: SERVERID=$s");
As long the optimal_server (i.e ping-time < threshold or well, EC2 availability zone) is kept up-to-date for each user data shard, this will send all requests according to server id till the maxconn is reached. And it fails over to round-robin when no cookie provided or the machine is down/out-of-capacity. HAproxy even holds a connection to reroute data to a different node for failover instead of erroring out.
And nobody said you had to do this for every user - do it only for a fraction that you care about :)
--“Many are stubborn in pursuit of the path they have chosen, few in pursuit of the goal.”
-- Friedrich Nietzsche
So bluesmoon wrote a blog entry on function currying in javascript. Read it first, if you've got no idea what I'm talking about.
But the example given there is hardly the *nice* one - you don't need a makeAdder(), you can sprinkle a little bit more magical pixie dust to make a maker. I remembered that I had a better sample lying around from early 2005, but unfortunately it wasn't quoted in my journal entry.
I couldn't find the exact code I wrote back then, but here's a re-do of the same idea.
function curried(f, args, arity)
{
return function() {
var fullargs = args.concat(toArray(arguments));
if(fullargs.length < arity)
{
/* recurse */
return curry(f).apply(null, fullargs);
}
else
{
return f.apply(null, fullargs);
}
};
}
function curry(f, arity)
{
if(!arity) arity = f.length;
return function() {
var args = toArray(arguments);
if(args.length < arity)
{
return curried(f, args, arity);
}
else
{
/* boring */
return f.apply(null, args);
}
};
}
Basically with the help of two closures (the two function() calls without names), I created a generic currying mechanism which can be used as follows.
function add(a,b) { return a+b;}
add = curry(add);
var add1 = add(1);
var c = add1(2);
Now, the hack works because of the arguments object available for use in every javascript function. Also every function, being an object as well, lets you look up the number of arguments (arity) it accepts by default. You can even make a full-class decorator, if you pay more attention to the scope (null, in my examples) passed to the function apply().
Here's the full code example.
--Things are are rarely simple. The function of good software is to make the complex appear to be simple.
-- Grady Booch.
About six years ago, in a classroom somewhere I was daydreaming while some out-of-work CS grad was trying to earn his rent, babbling about operating systems to kids who didn't want to be there. This is not about that classroom or what happened there. This is not about the memories I treasure from those days or the tumultous years that were to follow. This is about the here, now and virtual memory.
The essential problem writing code that is suppossed to be transparent is that you can't enforce your will on other code. For instance, when dealing with shared memory, it would be impossible to walk through & prevent all code using it from stomping all over the memory returned from the functions. The rather obvious solution is to deal with this is to make a copy for every case and hand it out. But doing that for all the data basically hammers over memory of the process and basically chews out the entire memory space. For a long time, I've been repeatedly debugging my entire code base with a hacked up valgrind with watchpoints. But eventually, there's that once-in-six-million errors which just won't be reproducible no matter what.
It's Not Real: The thing about memory addresses is that they're merely an abstraction. Once that idea settles down, things like fork(), CoW and mmap() start to make more and more sense. The translation from an address to a real page in memory is fairly complicated - but the actual details are irrelevant. Just like an address gets re-mapped to a different physical location when a process forks, it is possible to engineer a situation where multiple addresses point to the same location.
But why?: Sure, there's no real reason to have two addresses point to the same page, if they behave identically. But what if they behaved differently? With the help of mmap() or shmat() it's possible to create multiple virtual address spaces for the same real memory with different permissions. I discovered this particular trick thanks to someone pointing me to the Xcache Wiki. But it bears more explanation than there was. Here's how it's done.
char template[] = "/tmp/rowr.XXXXXX"; int fd = mkstemp(template); ftruncate(fd, size); void *rw = (void*)mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); void *ro = (void*)mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0); close(fd);
By mmap'ing the same fd twice, the same pages are available as RDONLY and RDWR addresses. These two addresses are different, but modifying the RW space will be reflected in the RO space - sort of like a read-only mirror of the data. A nearly identical example is possible with the use of shmat() with different permissions.
protect/unprotect: Since these are different address spaces, it is easy to distinguish between the two. Converting a RW ptr to RO, can also be accomplished simply with a little pointer arithmetic. The code would look somewhat like the version below without any bound checking. But ideally, some sort of check should be put in place to ensure double conversions don't cause errors.
int *p = (int*) rw; #define RO(p) (p) += (ro - rw); #define RW(p) (p) += (rw - ro); RO(p); *p = 42; /* causes segv */ RW(p); *p = 42; /* safe to do */
The essential task left is that all the pointers stored should be RO pointers. After storing the data, the pointers have to be flipped RO. After which, any memory walking would essentially walking over the RO "mirror" and cannot corrupt memory. All the unprotect operations would have to be inside a lock to ensure safe operation. And I do really have to thank Xcache for the idea - I'll finally have to stop hiding behind the "Zend did it!" excuse soon.
For those intrigued by my code fragments, but too lazy to fill in the blanks, here's a fully functional example.
--Don't worry about people stealing your ideas. If your ideas are any good, you'll have to ram them down people's throats.
-- Howard Aiken
I had a very simple problem. Actually, I didn't have a problem, I had a solution. But let's assume for the sake of conversation that I had a problem to begin with. I wanted one of my favourite hacked up tools to update in-place and live. The sane way to accomplish is called SUP or Simple Update Protocol. But that was too simple, you can skip ahead and poke my sample code or just read on.
I decided to go away from such a pull model and write a custom http server to suit my needs. Basically, I wanted to serve out a page feed using a server content push rather than clients checking back. A basic idea of what I want looks like this.
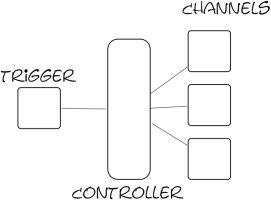
twisted.web: Twisted web makes it really easy to write an http webserver without ever wondering how an HTTP protocol line looks like. With a sub-class of twisted.web.resource.Resource, a class gets plugged into the server in-place & ready to serve a request. So, I implement a simple resource like this.
from twisted.internet import reactor, threads, defer, task
from twisted.web import resource, server
class WebChannel(resource.Resource):
isLeaf = 1
def __init__(self):
self.children = {}
def render_GET(self, request):
return "Hello World"
site = server.Site(WebChannel())
reactor.listenTCP(4071, site)
reactor.run()
Controller: The issue with the controller is mainly with the fact that it needs to be locked down to work as a choke point for data. Thankfully twisted provides twisted.python.threadable which basically lets you sync up a class with the following snippet.
class Controller(object): synchronized = ["add", "remove", "update"] .... threadable.synchronize(Controller)
loop & sleep: The loop and sleep is the standard way to run commands with a delay, but twisted provides an easier way than handling it with inefficient sleep calls. The twisted.internet.task.LoopingCall is designed for that exact purpose. To run a command in a timed loop, the following code "Just Works" in the background.
updater = task.LoopingCall(update) updater.start(1) # run every second
Combine a controller, the http output view and the trigger as a model pushing updates to the controller, we have a scalable concurrent server which can hold nearly as many connections as I have FDs per-process.
You can install twisted.web and try out my sample code which is a dynamic time server. Hit the url with a curl request to actually see the traffic or with firefox to see how it behaves. If you're bored with that sample, pull the svgclock version, which is a trigger which generates a dynamic SVG clock instead of boring plain-text. I've got the triggers working with Active-MQ and Mysql tables in my actual working code-base.
--Success just means you've solved the wrong problem. Nearly always.
I'm a very untidy tagger. I tag randomly and according to whim. Over the last year, thanks to my static tags plugin for pyblosxom, I have accumulated 150+ tags. Most of those are applied to hardly one or two entries and increasingly my tag cloud has been cluttered with such one-offs.
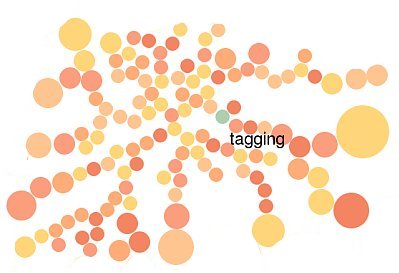
I spent an hour today checking out how to represent so much information into a single screen-ful. And I found a brilliant example in the penny packer extension.
So bye bye to the plaintext tags. Say guten tag to the Ishihara version.
--price tag on other side.
Frustration is my fuel. I spent an all nighter re-doing up one of my old valgrind patches to work with valgrind-3.3.1. This one was a doozy to patch up the first time (stealing rwalsh's code), but not quite very hard to keep up with the releases. The patch needs to be applied to the 3.3.1 source tree and memcheck rebuilt. It also requires the target code to be instrumented.
#include "valgrind/memcheck.h"
static int foobar = 1;
int main()
{
int *x = malloc(sizeof(int));
int wpid = VALGRIND_SET_WATCHPOINT(x, sizeof(int), &foobar);
*x = 10;
foobar = 0;
*x = 10;
VALGRIND_CLEAR_WATCHPOINT(wpid);
}
What has been added anew is the foobar conditional (you could just pass in NULL, if you always want an error). In this case the error is thrown only in first line modifying x. Setting the conditional to zero turns off the error reporting.
With the new APC-3.1 branch, I'm again hitting new race conditions whenever I change around stuff. I have no real way of debugging it in a controlled environment. But this patch will let me protect the entire shared memory space and turn on error flag as soon as control exits APC. Just being able to log all unlocked writes from Zend should go a long way in being able to track down race conditions.
Yup, frustration is my fuel.
--An intellectual is someone whose mind watches itself.
-- Albert Camus
DHCP makes for bad routing. My original problems with DHCP (i.e name resolution) has been solved by nss-mdns, completely replacing my hacky dns server - ssh'ing into hostname.local names work just fine.
But sadly, my WiFi router does not understand mdns hostnames. Setting up a tunnel into my desktop at home, so that I could access it from office (or australia for that matter), becomes nearly impossible with DHCP changing around the IP for the host.
UPnP: Enter UPnP, which has a feature called NAT Traversal. The nat traversal allows for opening up arbitrary ports dynamically, without any authentication whatsoever. Unfortunately, there doesn't seem to be any easily usable client I could use to send UPnP requests. But nothing stops me from brute-hacking a nat b0rker in raw sockets. And for my Linksys, this is how my POST data looks like.
<?xml version="1.0" ?>
<s:Envelope s:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" xmlns:s=
"http://schemas.xmlsoap.org/soap/envelope/">
<s:Body>
<u:AddPortMapping xmlns:u="urn:schemas-upnp-org:service:WANIPConnection:1">
<NewRemoteHost/>
<NewExternalPort>2200</NewExternalPort>
<NewProtocol>TCP</NewProtocol>
<NewInternalPort>22</NewInternalPort>
<NewInternalClient>192.168.1.2</NewInternalClient>
<NewEnabled>1</NewEnabled>
<NewPortMappingDescription>SSH Tunnel</NewPortMappingDescription>
<NewLeaseDuration>0</NewLeaseDuration>
</u:AddPortMapping>
</s:Body>
</s:Envelope>
And here's the quick script which sends off that request to the router.
--Air is just water with a lot of holes in it.
While working towards setting up the Hack Centre in FOSS.in, I had a few good ideas on what to do with my "free" time in there. The conference has come and gone, I haven't even gotten started and it looks like I'll need 36 hour days to finish these.
apt-share: I generally end up copying out my /var/cache/apt/archives into someone else's laptop before updating their OS (*duh*, ubuntu). I was looking for some way to automatically achieve it with a combination of an HTTP proxy and mDNS Zeroconf.
Here's how I *envision* it. The primary challenge is locating a similar machine on the network. That's where Zeroconf kicks in - Avahi service-publish and the OS details in the TXT fields sounds simple enough to implement. Having done that, it should be fairly easy to locate other servers running the same daemon (including their IP, port and OS details).
Next step would be to write a quick HTTP psuedo-cache server. The HTTP interface should provide enough means to read out the apt archive listing to other machines. It could be built on top of BaseHTTPServer module or with twisted. Simply put, all it does is send 302 responses to requests to .deb files (AFAIK, they are all uniquely named), with appropriate ".local" avahi hostnames. And assuming it can't find it in the local LAN, it works exactly like a transparent proxy and goes upstream.
Now, that's P2P.
WifiMapper: Unlike the standard wardriving toolkit, I wanted something to map out and record the signal strengths of a single SSID & associate it with GPS co-ordinates. A rather primitive way to do it would be to change the wireless card to run in monitor mode, iwlist scan your way through the place & map it using a bluetooth/USB gps device (gora had one handy).
But the data was hardly the point of the exercise. The real task was presenting it on top of a real topological map as a set of contour lines, connecting points of similar access. In my opinion, it would be fairly easy to print out an SVG file of the data using nothing more complicated than printf. But the visualization is the really cool part, especially with altitude measurements from the GPS. Makes it much simpler to survey out a conference space like foss.in than just walking around with a laptop, looking at the signal bars.
To put it simply, I've got all the peices and the assembly instructions, but not the time or the patience to go deep hack. If someone else finds all this interesting, I'll be happy to help.
And if not, there's always next year.
--Nothing is impossible for the man who doesn't have to do it himself.
-- A. H. Weiler
The "internet" is a series of tubes. So I decided to play plumber and hook up a few pipes the wrong way. What has been generally stopping me from writing too many web mashups has been the simple hurdle of making cross-domain data requests. While poking around pipes, I discovered that I could do cross-domain sourcing of data after massaging it into shape in pipes.yahoo.com.
After that blinding flash of the obvious, I picked on the latest web nitpick I've been having. Since I'm already hooked onto "The Daily Show", I've been watching (or trying to) it online from the Comedy Central website. But it is a very slow application, which shows a very small video surrounded by a lot of blank space - not to mention navigation in flash. A bit of poking around in HTTP headers showed a very simple backend API as well as an rss feed with the daily episodes. Having done a simple implementation as a shell script, I started on a Y! pipes version of it. The task was fairly intutive, though the UI takes some getting used to. Eventually, I got a javascript feed that I could just pull from any webpage, without requiring XMLHttpRequest or running into cross-domain restrictions.
You can poke around my pipe which has been used to create J002ube (say YooToobe ... so that j00z r l33t) to play the Daily Show videos. The player has zero lines of server side code and uses the Y! hosted pipes or client side code to accomplish everything.
More stuff coming up these pipes ...
--Whoever pays the piper calls the tune.
Browsing through my list of unread blog entries, I ran into one interesting gripe about lisp. The argument essentially went that the lisp parenthesis structure requires you to think from inside out of a structure - something which raises an extra barrier to understanding functional programming. And as I was reading the suggested syntax, something went click in my brain.
System Overload !!: I'm not a great fan of operator overloading. Sure, I love the "syntax is semantics" effect I can achieve with them, but I've run into far too many recursive gotchas in the process. Except for a couple of places, scapy packet assembly would be one place, I generally don't like code that uses it heavily. Still, perversity has its place.
So, I wrote a 4-line class which lets me use the kind of shell pipe syntax - as long as I don't break any python operator precedence rules (Aha!, gotcha land). The class relies on the python __ror__ operator overload. It seems to be one of the few languages that I know of which distinguishes the RHS and LHS versions of bitwise-OR.
class Pype(object):
def __init__(self, op, func):
self.op = op
self.func = func
def __ror__(self, lhs):
return self.op(self.func, lhs)
That was simple. And it is pretty simple to use as well. Here's a quick sample I came up with (lambdas; I can't live without them now).
double = Pype(map, lambda x : x * 2) ucase = Pype(map, lambda x: string.upper(x)) join = sum = Pype(reduce, lambda x,y: x+y) x = [1,2,3,4,5,6] | double | sum y = "is the answer" | ucase | join print x,y
And quite unlike the shell mode of pipes, this one is full of lists. Where in shell land, you'd end up with all operations talking in plain strings of characters (*cough* bytes), here the system talks in lists. For instance, the ucase pype actually gets a list with ['i','s' ...]. Keep that in mind and you're all set to go.
Oh, and run my sample code. Maybe there's a question it answers.
--Those who do not understand Unix are condemned to reinvent it, poorly.
-- Henry Spencer
A few months back I bought myself a cycle - a Firefox ATB. For nearly two months before heading out to Ladakh, I cycled to work. One of those days, I carried yathin's GPS along with me. So yesterday night, I dug up the GPX files, out of sheer boredom (and inspired by one of shivku's tech talks). After merging the tracks and waypoints, I managed to plot the track on a map with the help of some javascript. Here's how it looks.
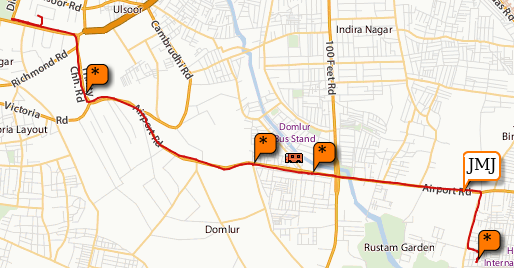
I have similar tracklogs from Ladakh, but they have upwards of 2000 points in each day, which do not play nicely with the maps rendering - not to mention the lack of maps at that zoom level. I need to probably try the Google maps api to see if they automatically remove nodes which resolve to the same pixel position at a zoom level.
I've put up the working code as well as the gpx parser. To massage my data into the way I want it to be, I also have a python gpx parser. And just for the record, I'm addicted to map/reduce/filter, lambdas and bisect.
--If you want to put yourself on the map, publish your own map.
Most wireless routers come without a DNS server to complement their DHCP servers. The ad-hoc nature of the network, keeps me guessing on what IP address each machine has. Even more annoying was the ssh man-in-the-middle attack warnings which kept popping up right and left. After one prolonged game of Guess which IP I am ?, I had a brainwave.
MAC Address: Each machine has a unique address on the network - namely the hardware MAC Address. The simplest solution to my problem was a simple and easy way to bind a DNS name to a particular MAC address. Even if DHCP hands out a different IP after a reboot, the MAC address remains the same.
Easier said than done: I've been hacking up variants of the twisted.names server, for my other dns hacks. To write a completely custom resolver for twisted was something which turned out to be trivial once I figured out how (most things are), except the dog ate all the documentation from the looks of it.
class CustomResolver(common.ResolverBase):
def _lookup(self, name, cls, type, timeout):
print "resolve(%s)" % name
return defer.succeed([
(dns.RRHeader(name, dns.A, dns.IN, 600,
dns.Record_A("10.0.0.9", 600)),), (), ()
])
Deferred Abstraction: The defer model of asynchronous execution is pretty interesting. A quick read through of the twisted deferred documentation explains exactly why it came into being and how it works. It compresses callback based design patterns into a neat, clean object which can then be passed around in lieu of a result.
But what is more interesting is how the defer pattern has been converted into a behind-the-scenes decorator. The following code has a synchronous function converted into an async defer.
from twisted.internet.threads import deferToThread
deferred = deferToThread.__get__
@deferred
def syncFunction():
return "Hi !";
The value a returned from the function is a Deferred object which can then have callbacks or errbacks attached to it. This simplifies using the pattern as well as near complete ignorance of how the threaded worker/pool works in the background.
53: But before I even got to running a server, I ran into my second practical problem. A DNS server has to listen at port 53. I run an instance of pdnsd which combines all the various dns sources I use and caches it locally. The server I was writing obviously couldn't replace it, but would have to listen in port 53 to work.
127.0.0.1/24: Very soon I discovered that the two servers can listen at port 53 on the same machine. There are 255 different IPs available to every machine - 127.0.0.2 is the same as localhost, but the different IP means that pdnsd listening on 127.0.0.1:53 does not conflict with this. Having reconfigured the two servers to play nice with each other, the really hard problem was still left.
RARP: The correct protocol for converting MAC addresses into IP addresses is called RARP. But it is obsolete and most modern OSes do not respond to RARP requests. One of the other solutions was to put a broadcast ping with the wanted MAC address. Only the target machine will recieve the packet and respond. Unfortunately, even that does not work with modern linux machines which ignore broadcast pings.
ARPing: The only fool-proof way of actually locating a machine is using ARP requests. This is required for the subnet to function and therefore does work very well. But the ARP scan is a scatter scan which actually sends out packets to all IPs in the subnet. The real question then was to do it within the limitations of python.
import scapy: Let me introduce scapy. Scapy is an unbelievable peice of code which makes it possible to assemble Layer 2 and Layer 3 packets in python. It is truly a toolkit for the network researcher to generate, analyze and handle packets from all layers of the protocol stack. For example, here's how I build an ICMP packet.
eth = Ether(dst='ff:ff:ff:ff:ff:ff') ip = IP(dst='10.0.0.9/24') icmp = ICMP() pkt = eth/ip/icmp (ans,unans)=srp(pkt)
The above code very simply sends out an ICMP ping packet to every host on the network (10.0.0.*) and waits for answers. The corresponding C framework code required to do something similar would run into a couple of hundred lines. Scapy is truly amazing.
Defer cache: The problem with flooding a network with ARP packets for every dns request is that it simply is a bad idea. The defer mechanism gives an amazing way to slipstream multiple DNS requests for the same host into the first MAC address lookup. Using a class based decorator ensures that I can hook in the cache with yet another decorator. The base code for the decorator implementation itself is stolen from the twisted mailing list.
Nested Lambdas: But before the decorator code itself, here's some really hairy python code which allows decorators to have named arguments. Basically using a lambda as a closure, inside another lambda, allowing for some really funky syntax for the decorator (yeah, that's chained too).
cached = lambda **kwargs: lambda *args, **kwarg2: \
((kwarg2.update(kwargs)), DeferCache(*args, **(kwarg2)))[1]
@cached(cachefor=420)
@deferred
def lookupMAC(name, mac):
...
The initial lambda (cached) accepts the **kwargs given (cachefor=420) which is then merged into the keyword arguments to the second lambda's args eventually passing it to the DeferCache constructor. It is insane, I know - but it is more commonly known as the curry pattern for python. But I've gotten a liking for lambdas ever since I've started using map/reduce/filter combinations to fake algorithm parallelization.
After assembling all the peices I got the following dnsmac.py. It requires root to run it (port 53 is privileged) and a simple configuration file in python. Fill in the MAC addresses of the hosts which need to be mapped and edit the interface for wired or wireless networks.
hosts = {
'epsilon': '00:19:d2:ff:ff:ff'
'sirius' : '00:16:d4:ff:ff:ff'
}
iface = "eth1"
server_address = "127.0.0.2"
ttl = 600
But it does not quite work yet. Scapy uses an asynchronous select() call which does not handle EINTR errors. The workaround is easy and I've submitted a patch to the upstream dev. With that patch merged into the scapy.py and python-ipy, the dns server finally works based on MAC address. I've probably taken more time to write the script and this blog entry than I'll ever spend looking for the correct IP manually.
But that is hardly the point  .
.
What's in a name? that which we call a rose
By any other name would smell as sweet;
-- Shakespeare, "Romeo and Juliet"
Over the last month, I've been poking around OpenMoko. The real reason was because toolz had a prototype phone with him. But the real reason I got anything done on the platform is because of the software emulation mode, with qemu-arm. The openmoko wiki has a fair bit of detail on running under QEMU - but if you just want pre-packaged ready to run QEMU images, take a look at jebba's pre-built images. All I've added to that is the qemu tun-tap network adapter ( -net nic -net tap ) so that I can scp stuff in & out of the phone image. Here's how the applications actually look on the emulator phone (it is *very* CPU heavy - if you have a Core2Duo or something, this would be a nice time to take a look at man taskset(1))
pnet on moko: Back in 2005, krokas had built the OE based packages for pnet. So essentially, building pnet ipks for OpenMoko is no different from building it for any other OE platform, especially because pnet hsa nearly no dependencies on anything beyong libc and libX11.
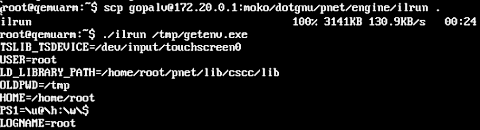
But the register asm() trick pnet uses to ensure that values like program counter and frame pointer are stored in the correct registers does not work on arm gcc-4.1.1. Aleksey has implemented a couple of solutions like the __asm__ barriers. But as of now, the engine is running in pure interpreter mode, which is not fast enough.
The emulator mode is pretty decent - even with the stock qemu-arm. If my interest keeps up, I'll probably try the OpenMoko patched qemu. I did build the whole toolchain and rootfs from scratch with MokoMakefile - but monotone is really painful to set up and the entire build takes a whopping 14 gigs of space on my disk. So if you're thinking of playing around with moko, don't try that first up :)
--Telephone, n.:
An invention of the devil which abrogates some of the advantages of making a disagreeable person keep his distance.
-- Ambrose Bierce
X11 programming is a b*tch. The little code I've written for dotgnu using libX11 must've damaged my brain more than second-hand smoke and caffeine overdoses put together. So, when someone asked for a quick program to look at the X11 window and report pixel modifications my immediate response was "Don't do X11". But saying that without offering a solution didn't sound too appealing, so I digged around a bit with other ways to hook into display code.
RFB: Remote Frame Buffer is the client-server protocol for VNC. So, to steal some code, I pulled down pyvnc2swf. But while reading that I had a slight revelation - inserting my own listeners into its event-loop looked nearly trivial. The library is very well written and has very little code in the protocol layer which assumes the original intention (i.e making screencasts). Here's how my code looks.
class VideoStream:
def paint_frame(self, (images, othertags, cursor_info)):
...
def next_frame(self):
...
class VideoInfo:
def set_defaults(self, w, h):
...
converter = RFBStreamConverter(VideoInfo(), VideoStream(), debug=1)
client = RFBNetworkClient("127.0.0.1", 5900, converter)
client.init().auth().start()
client.loop()
Listening to X11 updates from a real display is that simple. The updates are periodic and the fps can be set to something sane like 2 or 3. The image data is raw ARGB with region info, which makes it really simple to watch a particular window. The VNC server (like x11vnc) takes care of all the XDamage detection and polling the screen for incremental updates with that - none of that cruft needs to live in your code.
Take a look at rfbdump.py for the complete implementation - it is hardcoded to work with a localhost vnc server, but it should work across the network just fine.
--You can observe a lot just by watching.
-- Yogi Berra
I don't have flash on my machines. More than a mere security and convenience measure, it is one of those things enforced by Adobe themselves - by refusing to ship an EM64T/AMD64 build of its mozilla plugins. So when the flickr organizr went Javascript I was happy. But they took away a bit of code which made it really easy to rotate images - because you couldn't do it in Javascript.
But you can. I don't mean with some memory hogging clientside bit twiddling but with the now popular HTML 5 Canvas. So, with a few lines of Greasemonkey code, which you can pull from here, I can now push in image rotate previews back into flickr's organizr. The code has to be run outside greasemonkey land to get full access to the dom data, which I accomplish with the following script insertion.
var _s = document.createElement("script");
_s.appendChild(document.createTextNode(window.myFun.toSource() + "();"));
document.body.appendChild(_s);
And just in case you happen to be an IE user, you might want to see if EXCanvas can make my canvas code work decently there.
--enhance, v.:
To tamper with an image, usually to its detriment