About six years ago, in a classroom somewhere I was daydreaming while some out-of-work CS grad was trying to earn his rent, babbling about operating systems to kids who didn't want to be there. This is not about that classroom or what happened there. This is not about the memories I treasure from those days or the tumultous years that were to follow. This is about the here, now and virtual memory.
The essential problem writing code that is suppossed to be transparent is that you can't enforce your will on other code. For instance, when dealing with shared memory, it would be impossible to walk through & prevent all code using it from stomping all over the memory returned from the functions. The rather obvious solution is to deal with this is to make a copy for every case and hand it out. But doing that for all the data basically hammers over memory of the process and basically chews out the entire memory space. For a long time, I've been repeatedly debugging my entire code base with a hacked up valgrind with watchpoints. But eventually, there's that once-in-six-million errors which just won't be reproducible no matter what.
It's Not Real: The thing about memory addresses is that they're merely an abstraction. Once that idea settles down, things like fork(), CoW and mmap() start to make more and more sense. The translation from an address to a real page in memory is fairly complicated - but the actual details are irrelevant. Just like an address gets re-mapped to a different physical location when a process forks, it is possible to engineer a situation where multiple addresses point to the same location.
But why?: Sure, there's no real reason to have two addresses point to the same page, if they behave identically. But what if they behaved differently? With the help of mmap() or shmat() it's possible to create multiple virtual address spaces for the same real memory with different permissions. I discovered this particular trick thanks to someone pointing me to the Xcache Wiki. But it bears more explanation than there was. Here's how it's done.
char template[] = "/tmp/rowr.XXXXXX"; int fd = mkstemp(template); ftruncate(fd, size); void *rw = (void*)mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); void *ro = (void*)mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0); close(fd);
By mmap'ing the same fd twice, the same pages are available as RDONLY and RDWR addresses. These two addresses are different, but modifying the RW space will be reflected in the RO space - sort of like a read-only mirror of the data. A nearly identical example is possible with the use of shmat() with different permissions.
protect/unprotect: Since these are different address spaces, it is easy to distinguish between the two. Converting a RW ptr to RO, can also be accomplished simply with a little pointer arithmetic. The code would look somewhat like the version below without any bound checking. But ideally, some sort of check should be put in place to ensure double conversions don't cause errors.
int *p = (int*) rw; #define RO(p) (p) += (ro - rw); #define RW(p) (p) += (rw - ro); RO(p); *p = 42; /* causes segv */ RW(p); *p = 42; /* safe to do */
The essential task left is that all the pointers stored should be RO pointers. After storing the data, the pointers have to be flipped RO. After which, any memory walking would essentially walking over the RO "mirror" and cannot corrupt memory. All the unprotect operations would have to be inside a lock to ensure safe operation. And I do really have to thank Xcache for the idea - I'll finally have to stop hiding behind the "Zend did it!" excuse soon.
For those intrigued by my code fragments, but too lazy to fill in the blanks, here's a fully functional example.
--Don't worry about people stealing your ideas. If your ideas are any good, you'll have to ram them down people's throats.
-- Howard Aiken
I had a very simple problem. Actually, I didn't have a problem, I had a solution. But let's assume for the sake of conversation that I had a problem to begin with. I wanted one of my favourite hacked up tools to update in-place and live. The sane way to accomplish is called SUP or Simple Update Protocol. But that was too simple, you can skip ahead and poke my sample code or just read on.
I decided to go away from such a pull model and write a custom http server to suit my needs. Basically, I wanted to serve out a page feed using a server content push rather than clients checking back. A basic idea of what I want looks like this.
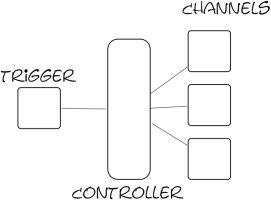
twisted.web: Twisted web makes it really easy to write an http webserver without ever wondering how an HTTP protocol line looks like. With a sub-class of twisted.web.resource.Resource, a class gets plugged into the server in-place & ready to serve a request. So, I implement a simple resource like this.
from twisted.internet import reactor, threads, defer, task
from twisted.web import resource, server
class WebChannel(resource.Resource):
isLeaf = 1
def __init__(self):
self.children = {}
def render_GET(self, request):
return "Hello World"
site = server.Site(WebChannel())
reactor.listenTCP(4071, site)
reactor.run()
Controller: The issue with the controller is mainly with the fact that it needs to be locked down to work as a choke point for data. Thankfully twisted provides twisted.python.threadable which basically lets you sync up a class with the following snippet.
class Controller(object): synchronized = ["add", "remove", "update"] .... threadable.synchronize(Controller)
loop & sleep: The loop and sleep is the standard way to run commands with a delay, but twisted provides an easier way than handling it with inefficient sleep calls. The twisted.internet.task.LoopingCall is designed for that exact purpose. To run a command in a timed loop, the following code "Just Works" in the background.
updater = task.LoopingCall(update) updater.start(1) # run every second
Combine a controller, the http output view and the trigger as a model pushing updates to the controller, we have a scalable concurrent server which can hold nearly as many connections as I have FDs per-process.
You can install twisted.web and try out my sample code which is a dynamic time server. Hit the url with a curl request to actually see the traffic or with firefox to see how it behaves. If you're bored with that sample, pull the svgclock version, which is a trigger which generates a dynamic SVG clock instead of boring plain-text. I've got the triggers working with Active-MQ and Mysql tables in my actual working code-base.
--Success just means you've solved the wrong problem. Nearly always.