APC user cache is cool. It provides an easy way to cache data, in the convenient form of hashes & more hashes within them, to share the data across processes. But it does lend itself to some abuses of shared memory which will leave your pager batteries dead, disk full of cores and your users unhappy. Eventually, the blame trickles down to splatter onto APC land. Maybe people using it didn't quite understand how the system works - but this blog entry is me washing my hands clean of this particular eff-up.
apc_fetch/_store: The source of the problem is how apc_fetch and apc_store are used in combination. For example, take a look at countries.inc from php.net. The simplified version of code looks like this.
if(!($data = apc_fetch('data'))) {
$data = array( .... );
apc_store('data', $data);
}
There is something slightly wrong with the above code, but the window for the race condition is too small to be even relevant. But all that changes the moment a TTL is associated with the user cache entry. For a system under heavy load, all hell breaks loose when a user cache entry expires due to TTL. Let me explain that with some pretty pictures and furious hand-waving.
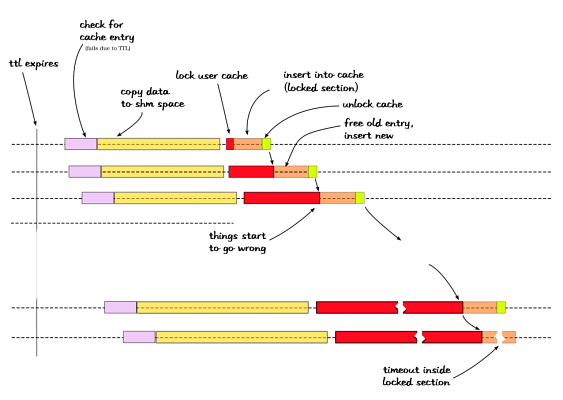
Each of the horizontal lines represent an individual apache process. The whole chain reaction is kicked off by a cache entry disappearing off the user cache. Every single process which hits the apc_fetch line (as above), now falls back into the corresponding apc_store. The apc_store operation does not lock the cache while copying data into shared memory. So all processes are actually allowed to proceed with the copy into shared memory (yellow block) in parallel. The actual insertion into the cache, however is locked. The lock is hit nearly simultaneously by all processes and sort of cascades into blocking the next process waiting on the lock.
Lock, lock, b0rk !: The cascade effect of waiting on the same lock eventually results in one process locking for so long that it hits the PHP execution timeout Or the user get bored and just presses disconnect from the browser. In apache prefork land, these generate a SIGPROF or SIGPIPE respectively. If for some reason that happens to be while code inside the locked section is being executed, apache might kill PHP before the corresponding unlock is called. And that's when it all goes south into a lockup.
So, when I ran into this for the first time, I did what every engineer should - damage limitation. The signals were by-passed by installing dummy signal handlers and deferring the signals while in locked sections. Somebody needs to rewrite that completely clean-room, before it is going to show up in the pecl CVS. The corresponding cache slam in the opcode cache is controlled by checking for cache busy and falling back to zend_compile - but the user cache has no such fallbacks.
I wish that was the only thing that was wrong with this. But I was slightly misleading when I said the copy into shared memory was parallel. The shared memory allocator still has locks and the actual allocation looks somewhat like this for 3 processes.
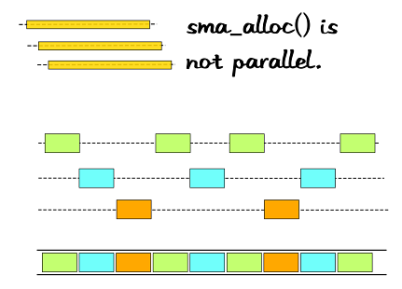
The allocations are interleaved both in time and in actual layout in memory (the bottom bar). So adjacent blocks actually belong to different processes, which is not exactly a very bad thing in particular. But as the previous picture illustrates, every single apc_store() call removes the previous entry and free's the space it occupies. Assuming there are only three processes, the free operation happens as follows.
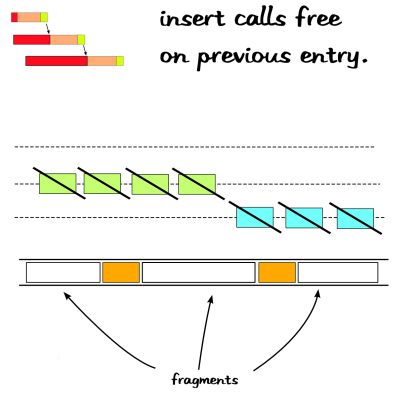
The process results in very heavy fragmentation, due to the large amount of overlap between the shared memory copy (apc_cache_store_zval) across processes. The problem neatly dove-tails into the previous one as the allocate & deallocate cost/time increases with fragmentation. Sooner or later, your apache, php and everything just gives up and starts dying.
There are a couple of solutions to this. Since APC 3.0.12, there is a new function apc_add which reduces the window for race conditions - after the first successful insertion of the entry, the execution time of the locked section is significantly reduced. But this still does not fix the allocation churn that happens before entering the locked section. The only safe solution is to never call an apc_store() from a user request context. A cron-job which hits a local URL to refresh cache data out-of-band is perfectly safe from such race conditions and memory churn associated.
But who's going to do all that ?
--In the Beginning there was nothing, which exploded.
-- Terry Pratchett, Lords and Ladies