As I walked into my room on Friday, I was planning to sit down and rewrite a fair bit of code in apc codebase. But my hard-disks had other plans for me. Both my 80 gig boot drive and my 200 gig sata drive had conked out, overheated in the middle of winter. The smaller drive had my /home and uncomitted work of about four months. The codebase had its cvs repository on the sata disk, which was thankfully working, though freezing up randomly. After a few hours of trying to copy out the cvsroot with a live CD, I tried to debug with smartctl on the dying drive.
bash# smartctl -d ata -l selftest /dev/sda === START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status hours LBA # 1 Short offline read failure 90% 2160 288074266 # 2 Extended offline read failure 90% 2155 290472493 # 3 Short offline read failure 90% 2155 290472493 bash# smartctl -d ata -A /dev/sda 5 Reallocated_Sector_Ct Pre-fail Always 41253
Basically a large number of sectors were bad and even an e2fsck couldn't complete on the disk without hitting the damaged sectors. After a lot of patient fiddling with debugfs, I managed to recover about 2/3rds of my cvsroot - but a fat lot of good that does. But in the process, I learned about a large number of tools available for data recovery, like badblock_guess, which reminds me of my b0rk-copy hacks. But as I said, I got a fair amount of data out of the second disk - but the first one was a total goner, not even spinning up on power-on.
Eventually, I went out, bought a couple of disks to replace these - 160 and 320 gigs, which are both SMART compatible. But to prevent the overheating from recurring, I tried to write my own alerts using inotify to warn me whenever the temperature exceeds limits. But as it turns out somebody has already done it and done it well - sensors-applet + hddtemp.
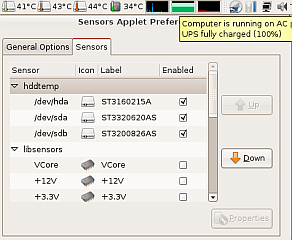
And this time, I'll be burning backups - I swear !
--The primary cause of failure in electrical appliances is an expired warranty.
-- Dave Barry