Before anyone gets grossed out, I'm talking about the third lesson into JIT 101. The first two being :-
- You do not talk about JITs
- Read lesson #1, again
The history aside, the lesson is about a simple feature of a CPU called cache. It is something that isn't even supposed to exist, if you are a programmer. Most people relegate cache to the realms of hardware and therefore never think about a cache while writing their code (which is bad cause it really matters for the last mile). Too many people think link-lists are always better than arrays - even when they are writing code for megahertz cpus (cache optimisations are a totally different book altogether).
Cache is a very important feature of CPU for a JIT programmer, a step below the instruction set and word-size. When you write any data to memory, you are writing to cache and ditto when you read. Most programmers only deal with data reads and writes. Life is not so simple for JIT folks, we write code into memory - a problem usually faced only by the OS loader, otherwise. But ever since the concept of self-modifying code died out, very few CPU designers ever design their instruction sets to accomodate the likes of us. So all we get to work with are a set of instructions to write data to memory via cache (exception being AMD64 which has a few Non Temporal instructions).
So what exactly is the problem if the code written stays on cache ?. For a novice, it'll look as if keeping it in cache will be faster. Is is, if all CPUs used a single cache for both data and instructions. CPUs like PowerPC, ARM, Sparc and IA64 have seperate caches for data and instruction set. It is interesting to note that i386 used a single cache for both and intel is forced to keep backward compatibility with a weird cache system (idiotic thunderbox!!). But AMD64 has it's own quirks which are great if you a performance enthusiast (boy, do I love AMD). Keeping them seperate makes it easier - as the instruction cache is read-only and therefore doesn't need any flush circuitry or checks for write-backs when invalidating. But on the other hand, RISC needed more instructions to feed it's pipeline per clock than CISC does (which might spend a lot of pipeline in operand fetch). All in all, intel screwed up - and IA64 bombed heavily (so did Pentium 4, if you look at how it compares to Pentium-3 archs like Pentium-M for insn per clock performance). Let's not beat that dead horse up here.
So all the binary code that you wrote to memory right now went to a data cache and is held there. When you actually try to execute these, they are pulled from the given address via the instruction cache from main memory. Now do you see the problem ?. But as I said before, OS loaders have the very same problem - so every CPU does have a workaround. It is called a cache flush. Write out your data and then flush the data you wrote back to memory.
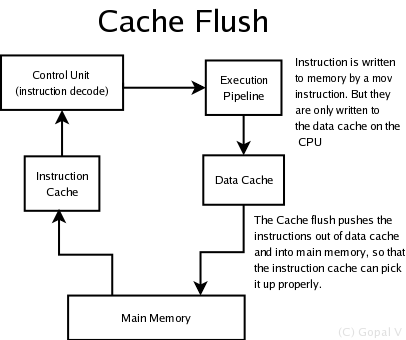
Here's how you do it - for PPC (copied from pnet engine).
while(count > 0)
{
/* Flush the data cache (coherence) */
__asm__ __volatile__ ("dcbf 0,%0" :: "r"(p));
/* Invalidate the cache lines in the instruction cache */
__asm__ __volatile__ ("icbi 0,%0" :: "r"(p));
p += cache_line_size;
count -= cache_line_size;
}
__asm__ __volatile__ ("sync");
__asm__ __volatile__ ("isync");
Of course, it is a costly operation. The sync is a memory ordering instruction (isync is for the instruction pipeline). The cache-line size is the size of the single block read in a single cache read (read: multiples of 8, till it starts working).
The irritating part of the above lesson is that the moment you run unflushed code in gdb, the code works. So if you JIT works inside gdb and SIGILLs outside, make sure you have flushed. I debugged the above code over an ssh-tunnel from office via sshd on port 443, through two squid HTTPS proxies , over which I ssh-ed into a DMZ (metadistribution.org) and into the PPC dev box (sweden, thanks to pvdabeel from Gentoo) - with a latency of over 500ms. And I liked it !!.
--
Real programmers leave *it* up